ELF 文件加载解析
参考资料:
程序内存布局
将源码(source code)编译为 ELF 文件后,其变成一个看似充满杂乱无章字节的文件。但可以将其分为程序(Program)和数据(Data)两部分:
- 程序:由一条条能被解码(Decode)的指令组成;
- 数据:存放着被程序控制读写的数据;
事实上,还能将文件划分为更小的单位:段(Section)。不同的段被放置在内存不同的位置上,这构成了程序的内存布局(Memory Layout),一种典型的程序相对内存布局如下:
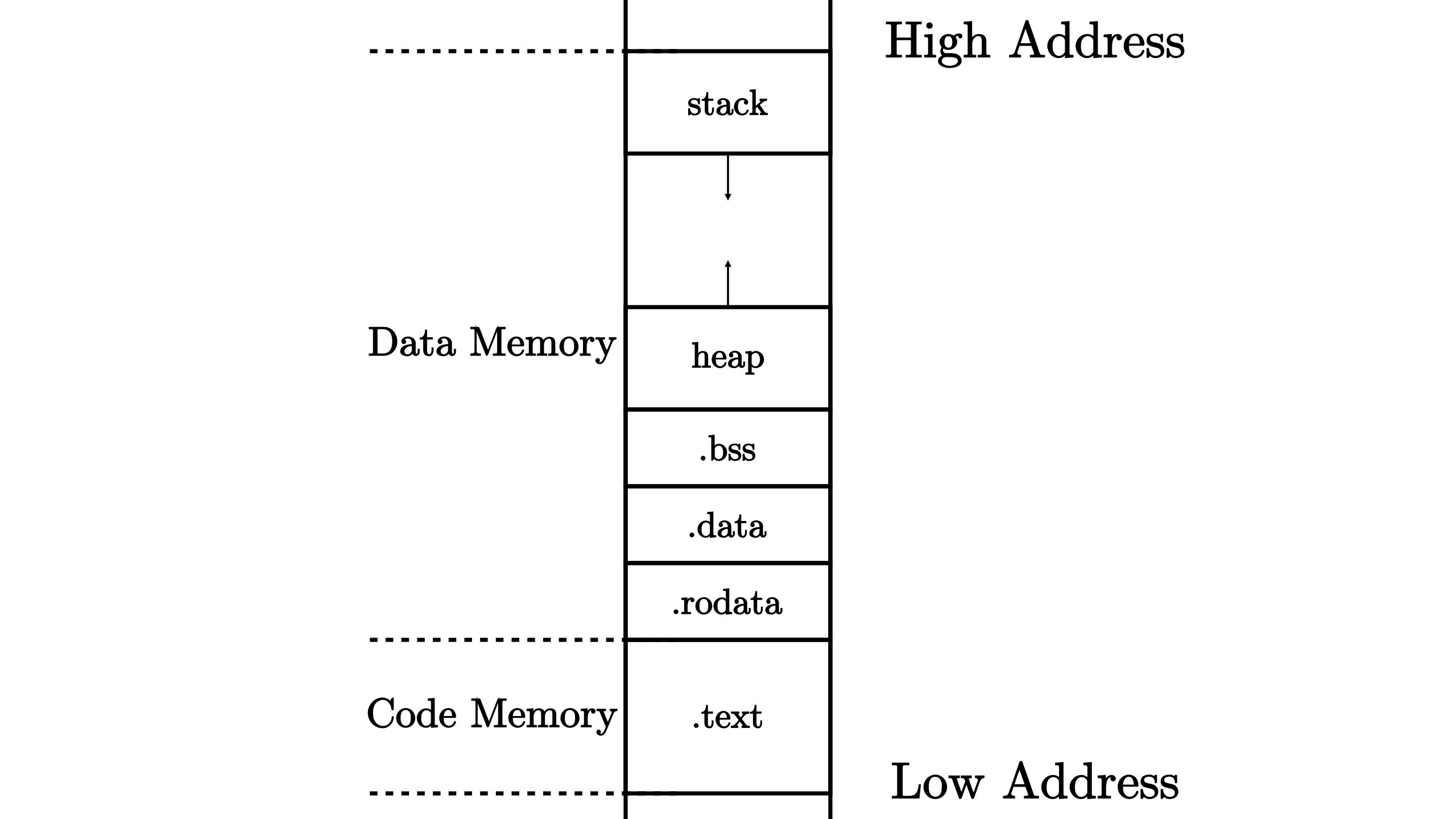
代码段:.text(存放所有程序)
数据段:
.rodata:(已初始化)只读的全局数据,常数、常量字符串;.data:(已初始化)可修改的全局数据;.bss:(未初始化/初始化为0)全局&静态数据,由程序加载器(Loader)代为清零;- 堆(heap):用来存放程序运行时动态分配的数据,向高地址增长,如:
new,melloc; - 栈(stack):用作函数调用上下文保存与恢复,每个函数的局部变量被编译器放于栈帧,向低地址增长。
函数视角上,能访问的变量:
- 函数入参和局部变量:保存在寄存器或函数栈帧内;
- 全局变量:保存在
.data和.bss,通过寄存器gp(x3)+offset来访问- 堆上的动态变量:运行时分配指针来访问,该指针可作为局部变量(栈帧)也可作为全局变量。
编译流程
编译主要有三个流程:
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
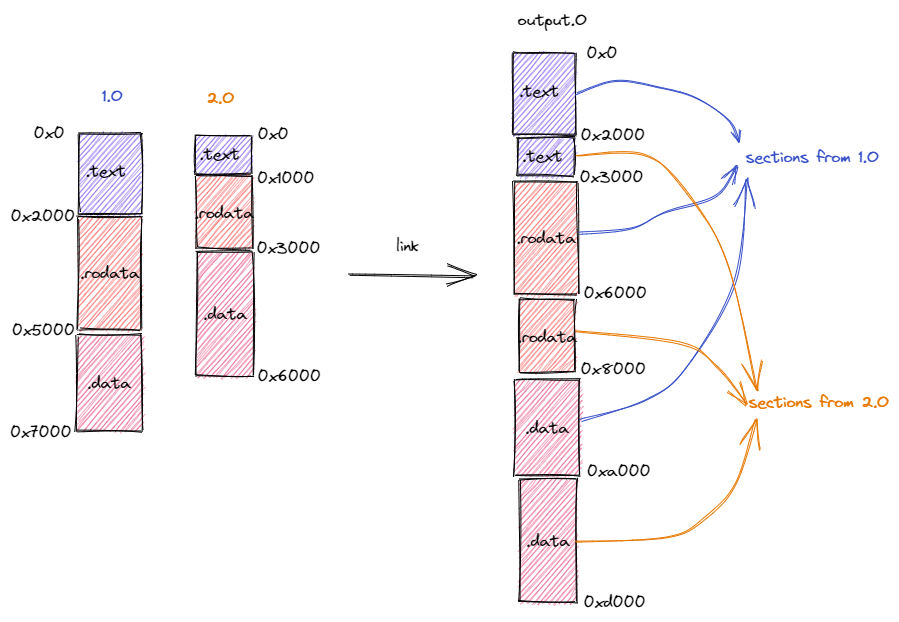
链接器所做的事情是将所有输入的目标文件整合成一个整体的内存布局。在此期间链接器主要完成两件事情:
- 将来自不同目标文件的段在目标内存布局中重新排布。如下图所示,在链接过程中,分别来自于目标文件
1.o和2.o段被按照段的功能进行分类,相同功能的段被排在一起放在拼装后的目标文件output.o中。注意到,目标文件1.o和2.o的内存布局是存在冲突的,同一个地址在不同的内存布局中存放不同的内容。而在合并后的内存布局中,这些冲突被消除; - 将符号替换为具体地址。
备注:
- 这里的符号(Symbol)指什么呢?
我们知道,在我们进行模块化编程的时候,每个模块都会提供一些向其他模块公开的全局变量、函数等供其他模块访问,也会访问其他模块向它公开的内容。要访问一个变量或者调用一个函数,在源代码级别我们只需知道它们的名字即可,这些名字被我们称为符号。取决于符号来自于模块内部还是其他模块,我们还可以进一步将符号分成内部符号和外部符号。
然而,在机器码级别(也即在目标文件或可执行文件中)我们并不是通过符号来找到索引我们想要访问的变量或函数,而是直接通过变量或函数的地址。例如,如果想调用一个函数,那么在指令的机器码中我们可以找到函数入口的绝对地址或者相对于当前 PC 的相对地址。
- 那么,符号何时被替换为具体地址呢?
因为符号对应的变量或函数都是放在某个段里面的固定位置(如全局变量往往放在
.bss或者.data段中,而函数则放在.text段中),所以我们需要等待符号所在的段确定了它们在内存布局中的位置之后才能知道它们确切的地址。当一个模块被转化为目标文件之后,它的内部符号就已经在目标文件中被转化为具体的地址了,因为目标文件给出了模块的内存布局,也就意味着模块内的各个段的位置已经被确定了。**然而,此时模块所用到的外部符号的地址无法确定。**我们需要将这些外部符号记录下来,放在目标文件一个名为符号表(Symbol table)的区域内。由于后续可能还需要重定位,内部符号也同样需要被记录在符号表中。
外部符号需要等到链接的时候才能被转化为具体地址。假设模块 1 用到了模块 2 提供的内容,当两个模块的目标文件链接到一起的时候,它们的内存布局会被合并,也就意味着两个模块的各个段的位置均被确定下来。此时,模块 1 用到的来自模块 2 的外部符号可以被转化为具体地址。
同时我们还需要注意:两个模块的段在合并后的内存布局中被重新排布,其最终的位置有可能和它们在模块自身的局部内存布局中的位置相比已经发生了变化。因此,每个模块的内部符号的地址也有可能会发生变化,我们也需要进行修正。上面的过程被称为重定位(Relocation)。
这个过程形象一些来说很像拼图:由于模块 1 用到了模块 2 的内容,因此二者分别相当于一块凹进和凸出一部分的拼图,正因如此我们可以将它们无缝地拼接到一起。
ELF 文件视图
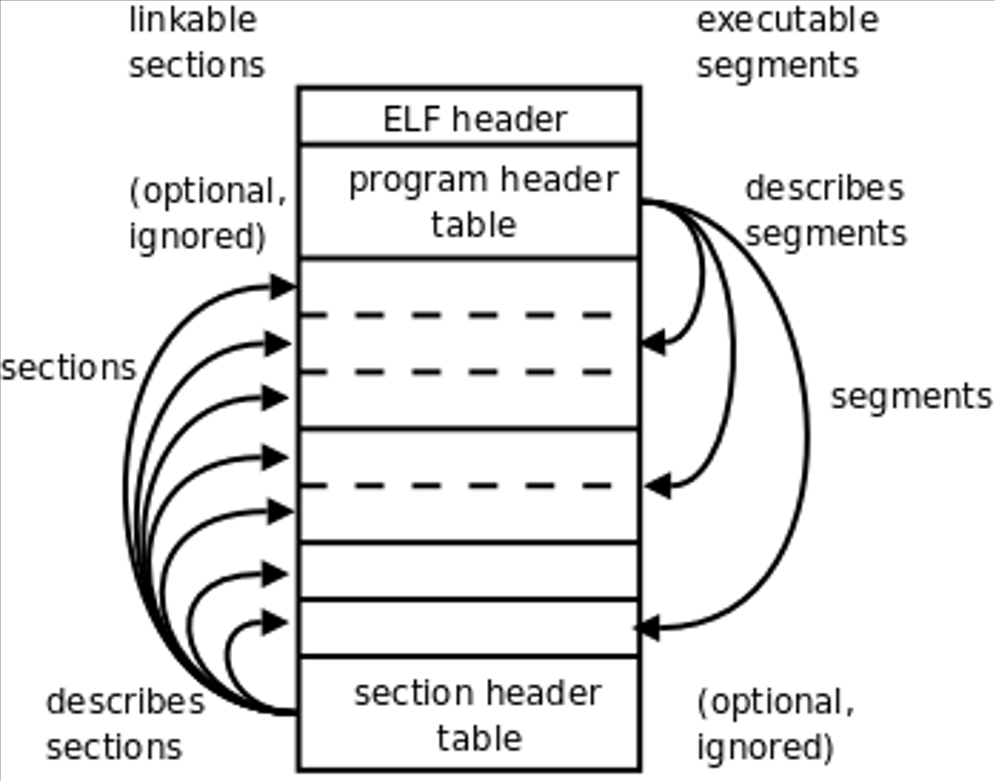
一个 ELF 可执行文件可以通过两个视图去分析:
- 链接视图(Link View):以节(Section)为单位;
- 执行视图(Exec View):以段(Segment)为单位;
ELF 头信息(ELF header)
ELF文件的最开始是ELF文件头(ELF Header):包含了描述整个文件的基本属性。ELF文件分为文件头和文件体两部分:
- 先用 ELF header 从文件全局概要出程序中程序头表(phdr)、节头表(shdr)的位置和大小等信息;
- 然后从程序头表和节头表中分别解析出各个段和节的位置和大小等信息;
typedef struct elf64_hdr {
unsigned char e_ident[EI_NIDENT];
Elf64_Half e_type; // 文件类型
Elf64_Half e_machine; // 体系结构
Elf64_Word e_version; // 版本信息
Elf64_Addr e_entry; // 虚拟地址入口
Elf64_Off e_phoff; // phdr在文件内偏移量
Elf64_Off e_shoff; // shdr在文件内偏移量
Elf64_Word e_flags; // 处理器相关标志
Elf64_Half e_ehsize; // elf header大小
Elf64_Half e_phentsize; // phdr大小
Elf64_Half e_phnum; // 段个数
Elf64_Half e_shentsize; // shdr大小
Elf64_Half e_shnum; // 节个数
Elf64_Half e_shstrndx;
} Elf64_Ehdr;
e_ident[EI_NIDENT]是16字节大小的数组,用来表示ELF字符等信息,开头四个字节是固定不变的elf文件魔数(Magic Number):
e_ident[0..3] = 0x7fELF // 魔数
e_ident[4] // 位数:1(32bit), 2(64bit)
e_ident[5] // 大小端:1(LSB), 2(MSB)
e_ident[6] // 版本
e_ident[7-15] // 保留位
e_type(2字节)指定了文件类型:
// include/uapi/linux/elf.h
#define ET_NONE 0 // 未知目标文件格式
#define ET_REL 1 // 可重定位文件
#define ET_EXEC 2 // 可执行文件
#define ET_DYN 3 // 动态共享目标文件
#define ET_CORE 4 // core文件,程序崩溃时内存映像的转储格式
#define ET_LOPROC 0xff00 // 特定处理器文件的扩展下界
#define ET_HIPROC 0xffff // 特定处理器文件的扩展上界
e_machine(2字节):描述目标文件体系结构:
// include/uapi/linux/elf-em.h
#define EM_NONE 0
#define EM_M32 1
#define EM_SPARC 2
#define EM_386 3
#define EM_68K 4
#define EM_88K 5
#define EM_486 6 /* Perhaps disused */
#define EM_860 7
#define EM_MIPS 8 /* MIPS R3000 (officially, big-endian only) */
/* Next two are historical and binaries and
modules of these types will be rejected by
Linux. */
#define EM_MIPS_RS3_LE 10 /* MIPS R3000 little-endian */
#define EM_MIPS_RS4_BE 10 /* MIPS R4000 big-endian */
#define EM_PARISC 15 /* HPPA */
#define EM_SPARC32PLUS 18 /* Sun's "v8plus" */
#define EM_PPC 20 /* PowerPC */
......
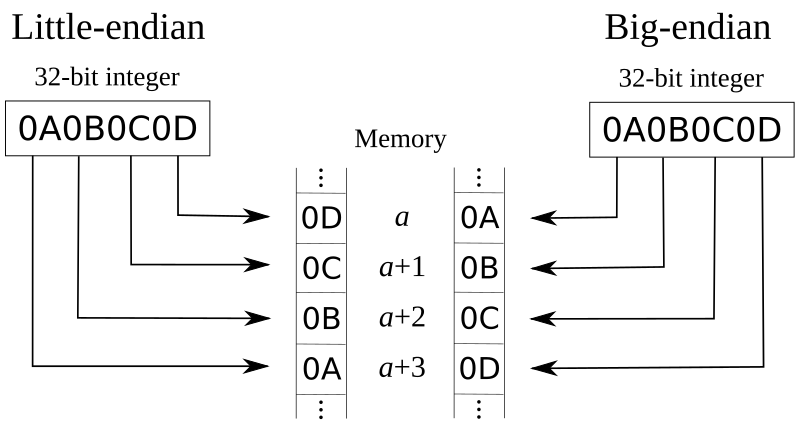
端序或尾序(Endianness),又称字节顺序。在计算机科学领域中,指电脑内存中或在数字通信链路中,多字节组成的字(Word)的字节(Byte)的排列顺序。字节的排列方式有两个通用规则:例如,将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序(little-endian);反之则称大端序(big-endian)。常见的 x86、RISC-V 等架构采用的是小端序。
程序头表(phdr)
程序头表(也称为段表)是一个描述文件中各个段的数组,程序头表描述了文件中各个段在文件中的偏移位置及段的属性等信息;从程序头表里可以得到每个段的所有信息,包括代码段和数据段等:
typedef struct elf64_phdr {
Elf64_Word p_type; // 程序段类型
Elf64_Word p_flags; // 本段相关标志
Elf64_Off p_offset; // 本段在文件内起始偏移
Elf64_Addr p_vaddr; // 本段在内存中虚拟地址
Elf64_Addr p_paddr; // 本段在内存中物理地址
Elf64_Xword p_filesz; // 段在文件中大小
Elf64_Xword p_memsz; // 段在内存中大小
Elf64_Xword p_align; // 本段的对齐方式
} Elf64_Phdr;
对于p_type(4字节):指明段类型
// include/uapi/linux/elf.h
#define PT_NULL 0 // 忽略
#define PT_LOAD 1 // 可加载程序段
#define PT_DYNAMIC 2 // 动态链接信息
#define PT_INTERP 3 // 动态加载器名称
#define PT_NOTE 4 // 辅助的附加信息
#define PT_SHLIB 5 // 保留
#define PT_PHDR 6 // 程序头表
#define PT_TLS 7 /* Thread local storage segment */
#define PT_LOOS 0x60000000 /* OS-specific */
#define PT_HIOS 0x6fffffff /* OS-specific */
#define PT_LOPROC 0x70000000
#define PT_HIPROC 0x7fffffff
对于p_flag(4字节):指明段标志
// include/uapi/linux/elf.h
#define PF_R 0x4 // 可读
#define PF_W 0x2 // 可写
#define PF_X 0x1 // 可执行