前言
About me:
- Github | lancerstadium
- Email: lancerstadium@163.com
开天辟地,先来一段hello, world:
#include <stdio.h>
int main() {
printf("Hello, world!\n");
return 0;
}
计算机体系结构
- 这里是计算机体系结构
计算机组成原理
COA, Computer Organization and Architecture
第一章 计算机系统体系结构
术语
- 指令集体系结构(ISA):描述了程序员看到了计算机的抽象视图,定义了汇编语言和编程模型。(没有考虑电路、电子元件的实现)
- 微体系结构:描述了一种指令集体系结构的实现方式,关注计算机的内部设计。
- 系统体系结构:关注包括处理器、存储器、总线和外设在内的整个系统。
计算机系统体系结构所涉及的内容
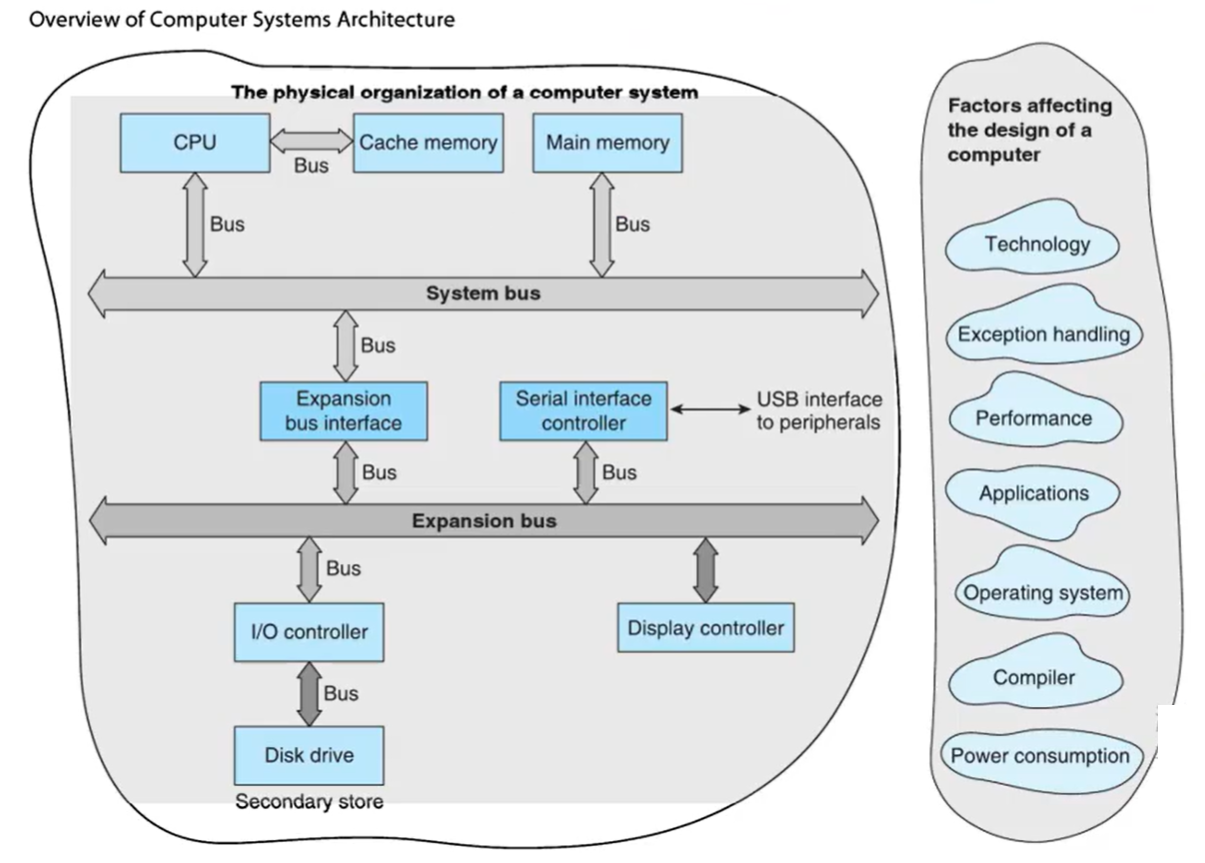
- 计算机系统的物理组织:
- CPU
- 主存
- 系统总线
- Cache
- 外设:
- 拓展总线
- 串行接口控制器:USB接口到外设
- I/O控制器
- 显示控制器
- 设计因素:
- 技术
- 异常处理
- 性能
- 应用
- 操作系统
- 编译器
- 功耗
1.1 什么是计算机体系结构
-
计算机系统包括:
- 中央处理单元CPU:读取、执行程序
- 存储器:保存程序和数据
- IO子系统:显示器、鼠标、键盘
-
处理器(CPU)是实际执行程序的组件;微处理器实在单个硅片上实现的CPU,微处理器构建的计算机叫微机。
-
计算机性能不仅取决于CPU也取决于其他子系统性能,若不能高效数据传输,仅仅提高CPU性能无意义。
简单通用计算机结构
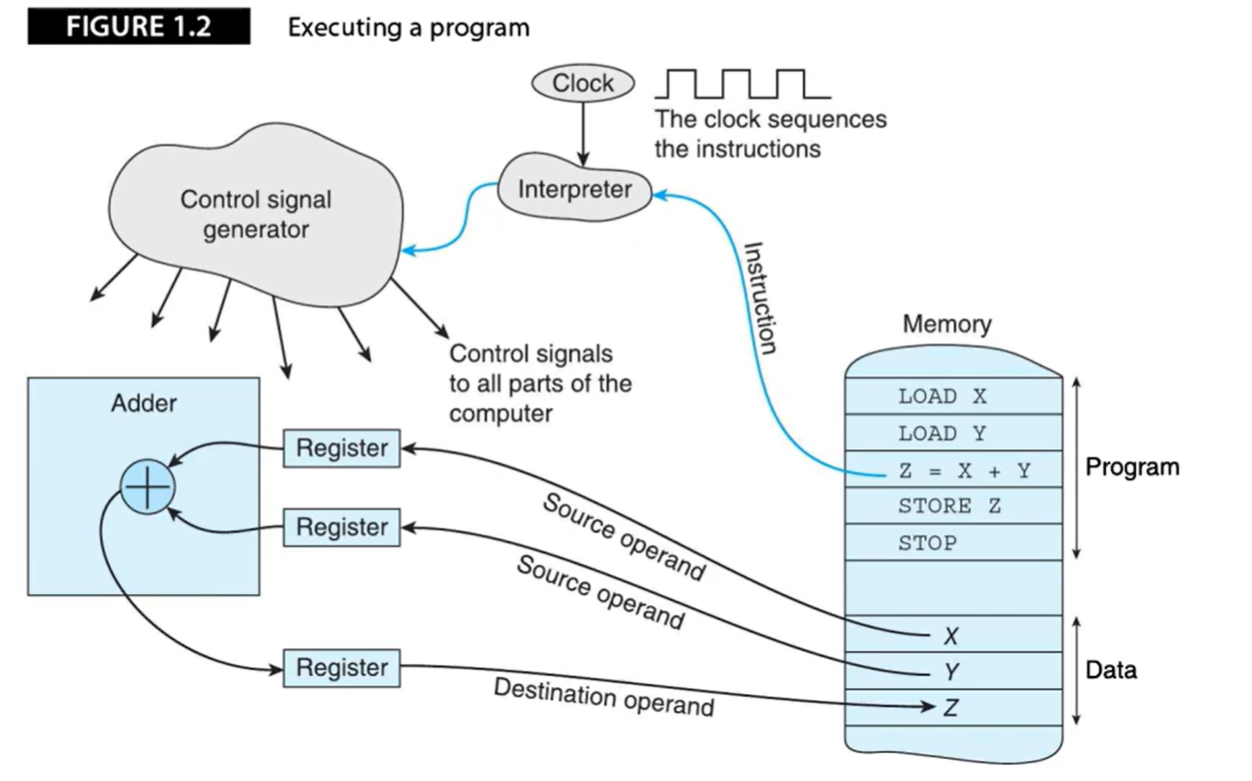
一个简易的计算机结构如下:
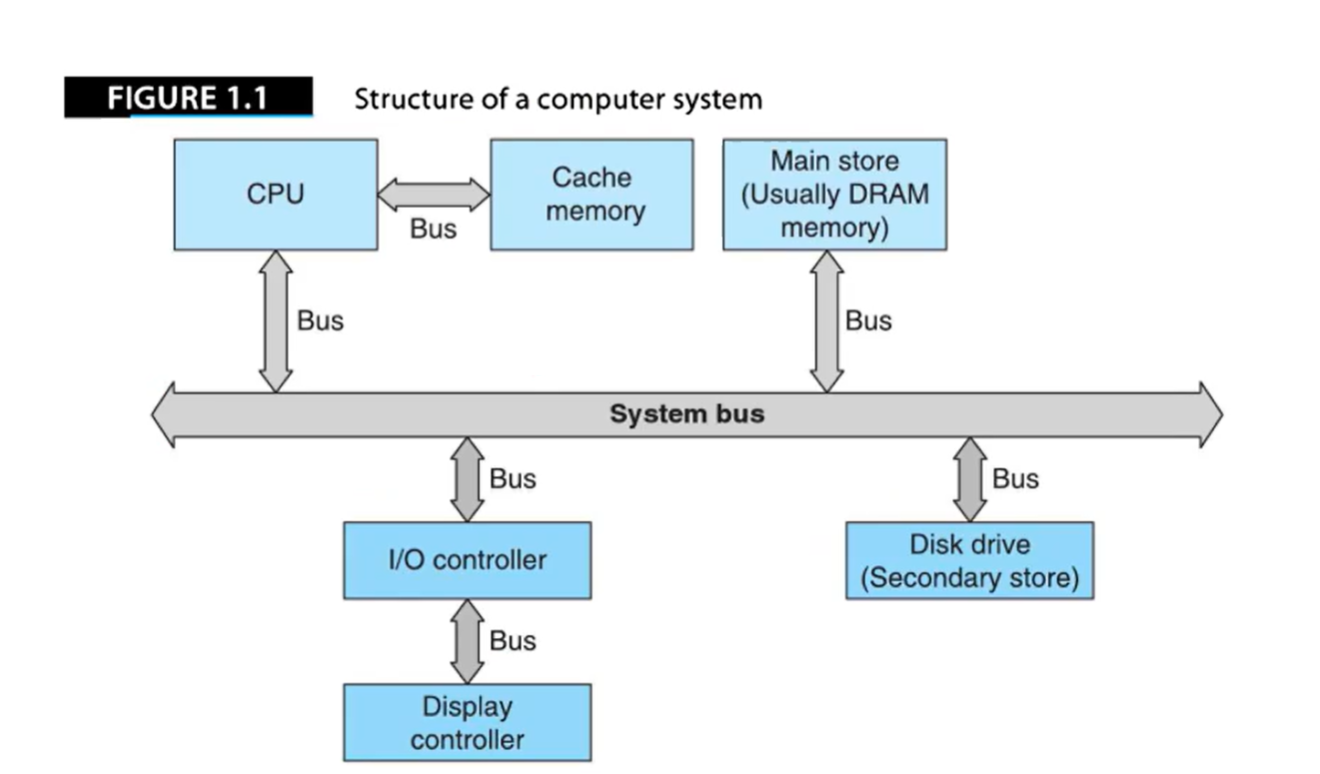
- 信息(程序Program、数据Data)保存在存储器中,为实现不同目标,计算机会使用不同类型的存储器(Cache、主存、辅存等)。
- Cache(高速缓存)存储常用信息,主存存储大量工作信息,辅存(磁盘、CD-ROM)存储海量信息。
- 计算机各个子系统通过总线(Bus)连接在一起,数据通过总线从计算机中一个位置传递到另一个位置。
下图描述了一台接收并处理输入信息、产生输出结构的可编程数字计算机:
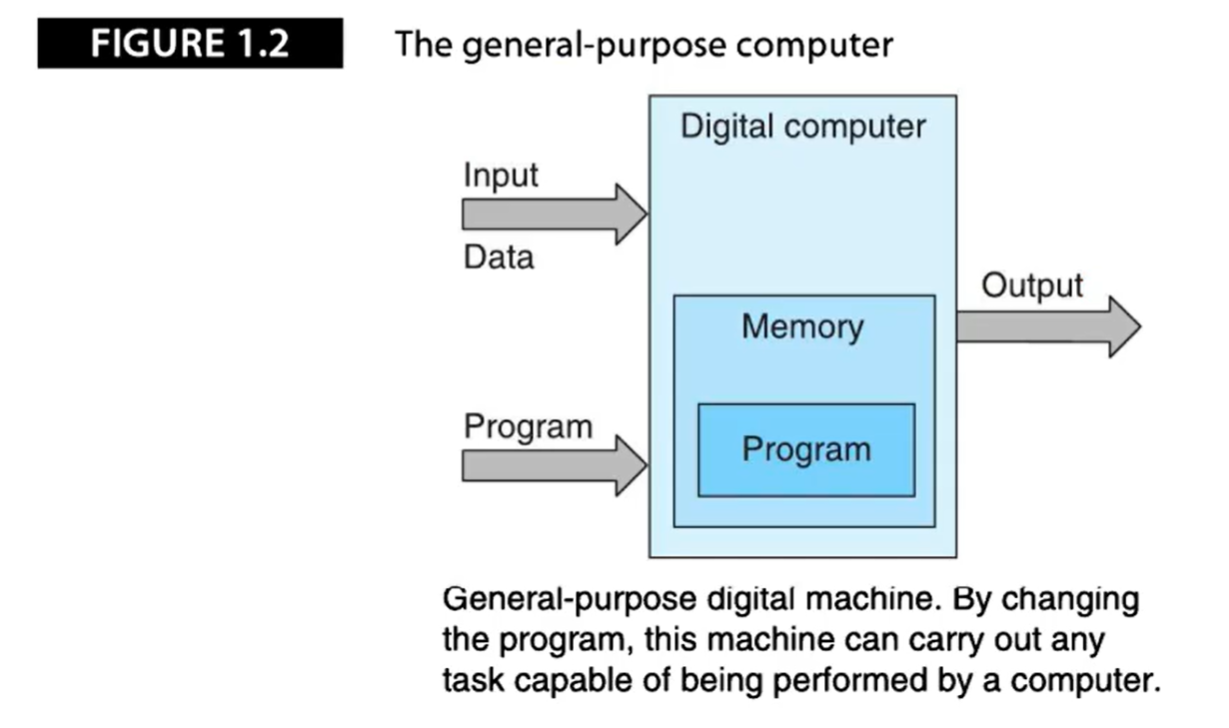
可编程计算机接收两种类型的输入:
- 要处理的数据(Data)
- 定义处理数据的程序(Program)
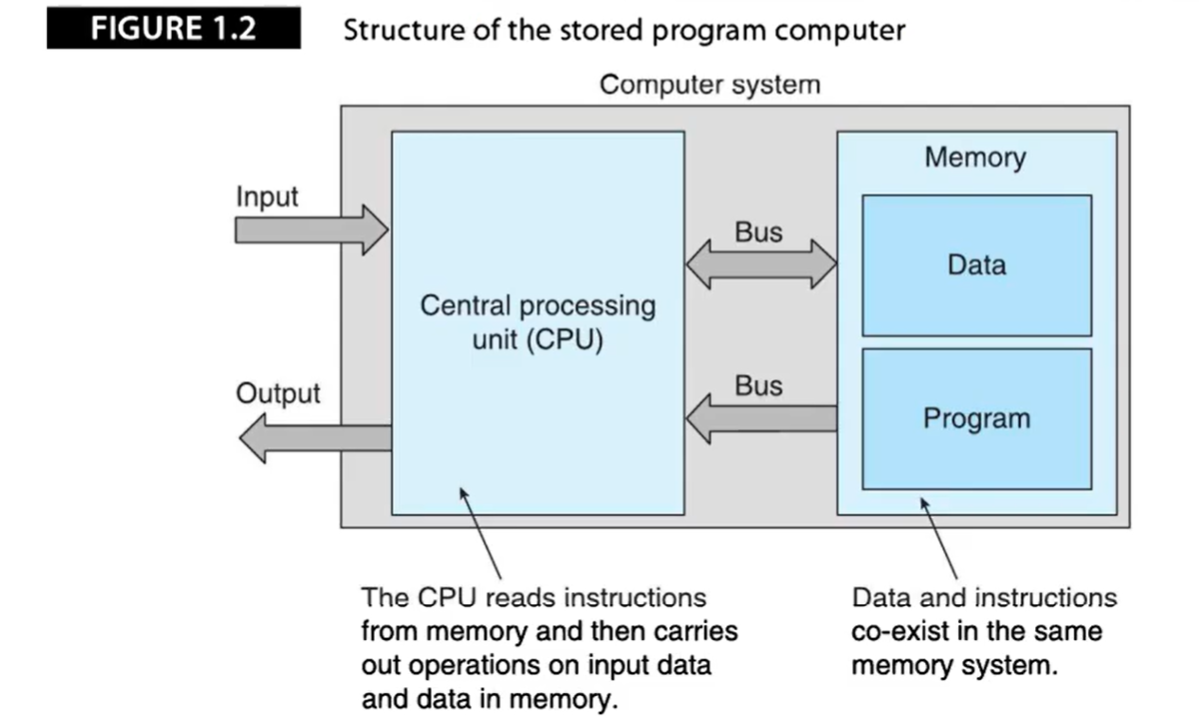
数字计算机结构可分为两部分:
- 中央处理单元(CPU):读取程序完成指定操作
- 存储器系统:保存程序与程序处理、产生的数据
另外,寄存器(Register)是CPU内部用来存放数据的存储单元;时钟(Clock)提供了脉冲流,所有内部操作都在时钟脉冲的触发下进行。时钟频率是决定计算机速度的一个因素。(CPU主频)
程序的执行过程
程序的执行过程如下:
while(0) {
ifetch(); // 取指令
decode(); // 解码
exec(); // 执行
}
计算机基本指令
六条基本指令:
MOV A, B ; 将B的值复制到A
LOAD A, B ; 将存储单元B的值复制到寄存器A
STORE A, B ; 将寄存器B的值复制到存储单元A
ADD A, B ; A与B相加,结果保存到A
TEST A ; 测试A的值是否为0
BEQ Z ; 若最后一次测试结果为TRUE,执行Z处代码,否则继续执行
1.2 体系结构与组成
计算机体系结构(Computer Architecture)含有结构(structure)的意思。之所以定义计算机体系结构,因为不同用户会从不同角度看待计算机。CA通常被认为是程序员视角中的计算机,程序员所看到的是计算机的抽象视图。
计算机组成(Computer Organization)表示CA的具体实现。(抽象变为具体)
本书使用 CA 表示计算机抽象指令集 ISA,使用 CO 表示计算机实际硬件实现。
寄存器
寄存器(Register)是用来存放一个单位的数据或字数据的存储单位。寄存器通常用它所保存数据的位数来描述(8位、16位、32位、64位)。
寄存器与存储器中的字存储单元没有本质区别。二者实际区别在于:寄存器位于CPU内,访问速度更快。
机器码 & 汇编语言
计算机上执行的代码表示为二进制0和1组成的串,被称为机器码(Machine Code)。每种计算机只能执行一种特定机器码。
将机器码解释成人类可阅读的形式,则为汇编语言(Assembly Language),机器码与汇编语言一一对应。
能在不同计算机运行,与底层 CA 无关系的代码叫做高级语言(如:C,Java)。执行之前,高级语言必须被编译为计算机本地机器码。
时钟
绝大多数数字电子电路都带有一个时钟,用来生成连续的、间隔固定的电脉冲流。之所以被称为时钟(Clock)是因为可用这些电脉冲来计时或确定计算机内所有事件的顺序。
RISC & CISC
RISC(精简指令集)CA:
- 设计策略:少量指令完成最少的简单操作
- 缺点:程序设计更难,复杂指令需要用简单指令模拟
- 应用:ARM、RISCV
CISC(复杂指令集)CA:
- 设计策略:使用大量指令,包括复杂指令
- 优点:程序设计更容易
- 缺点:CPU和控制单元电路复杂
- 应用:Intel 奔腾、x86_64
1.3 计算机发展
机械计算机
机电式计算机
早期的电子计算机
微机和PC革命
摩尔定律
乱序执行
程序中指令不许一条接一条安装程序中的出现顺序执行:
#1 x = 2 * c
#2 y = c + 4
#3 z = x + y
#4 a = 4 * c
#5 p = c - 3
有时可以通过改变指令的执行顺序提高计算机的速度:#4 和 #5 可以在任何时候执行,但 #3 必须在 #1 和 #2 结束后执行。
存储技术发展
覆盖电容旋转的磁鼓
阴极射线管
铁氧体磁芯存储器
磁盘
光存储器(DVD等)
成本变低,存储容量变高
普适计算(泛在计算)
物联网(IoT):手机、电视、冰箱等等
1.4 存储程序计算机
问题描述
十进制数串23277366664792221,其中有一些值相通的数字连续出现(如连续的2个7,4个6和3个2),我们的问题十分简单:找出最大游程,即同一个数字连续出现的最大次数。
为了简化问题,假设数串长度大于3,设计一个计算机来处理数串,每次读一个数并计算最大游程:
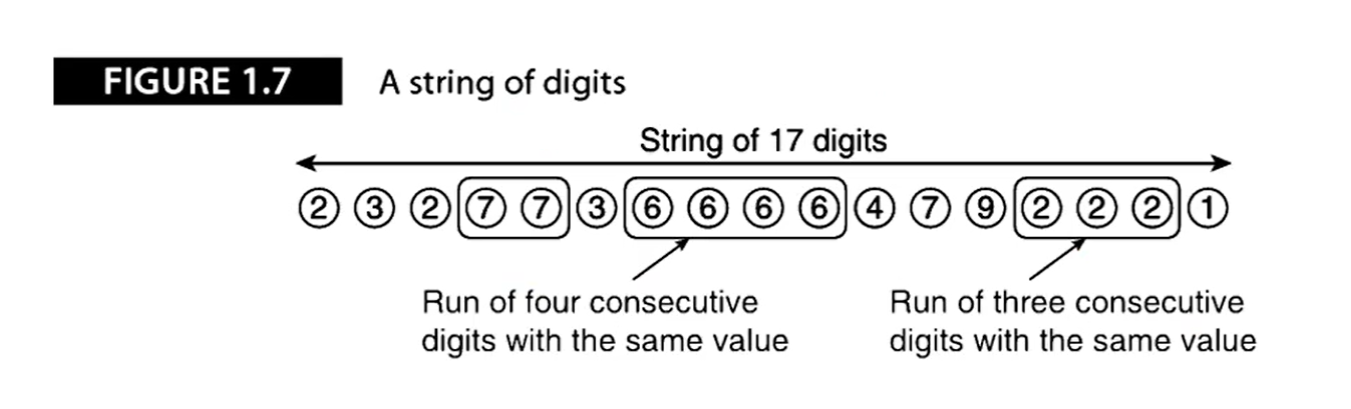
解决方法
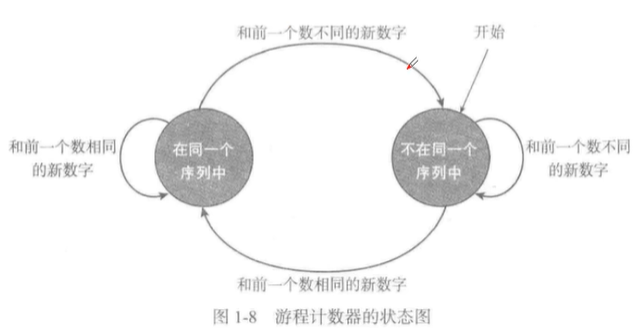
从数串的左边逐个检查数字,在任何一个位置,都会得到两个结果之一:要么这个数和前一个相同,序列还在增长;要么这个数与上一个不同,前一个序列结束,一个新的序列开始。
- 状态图帮助我们解决这个问题:
计算机组成与设计
参考资料:
教材:Computer Organization and Design: The Hardware/Software Interface, RISC-V Edition
第一章 计算机抽象及相关技术
CA的八个伟大思想
面向摩尔定律的设计
Moore's law:计算机架构师必须预测其设计完成时的工艺水平,而不是开始时的工艺水平。
使用抽象简化设计
Abstraction:隐藏底层细节提供高层更简单的模型。
加速经常性事件
Make the common case fast:远比优化罕见清空能更好提升性能。
通过并行提升性能
Parallelism:并行计算 YYDS
通过流水线提高性能
Pipelining:各司其职,重复工作,压榨时间。
通过预测提升性能
Forecast:假设从预测错误中恢复的代价并不高,预测若准确则执行更快。
存储层次
Hierarchy of memory:速度快容量小顶层,速度慢容量大底层。
通过冗余提高可靠性
Redundancy:冗余组件发生故障时可以替代失效组件并帮助检测故障。
性能
性能指标
CPU执行时间(CPU exec time):也称CPU时间,执行某一任务在CPU上花费的时间。
用户CPU时间(User time):程序本身所花费的CPU时间。
系统CPU时间(System time):为执行程序花费在操作系统上的时间。
时钟周期长度(Cycle length):每个时钟周期持续的时间,时钟频率(Clock Frequency)的倒数。
时钟周期数(CPU cycle):处理器时钟在固定频率下运行。
CPU_exec_time = CPU_cycles * Cycle_length
指令数(Number of instructions):程序执行所需要的指令总数。
指令平均时钟周期数(CPI):平均每个指令所需要的时钟周期。
CPU_exec_time = N_insts * CPI * Cycle_length
每秒百万条指令数(MIPS):程序速度的一种度量。(无法用 MIPS 比较不同 ISA 的计算机;其次,一台计算机上不同程序也有不同的 MIPS)
MIPS = N_insts / (exec_time * 10^6) = Clock_frequency / (CPI * 10^6)
[例] 代码片段比较:请问哪个代码序列执行的指令数更多?哪个执行速度更快?每个代码序列 CPI 分别是多少?
每列指令的 CPI:
| 指令类别 | A | B | C |
|---|---|---|---|
| CPI | 1 | 2 | 3 |
两段代码序列所需指令数量分别如下:
| 指令类别 | A | B | B |
|---|---|---|---|
| 序列1 | 2 | 1 | 2 |
| 序列2 | 4 | 1 | 1 |
答:序列1共执行 2+1+2=5 条指令,序列2共执行 4+1+1=6 条指令。
CPI_1 = (2*1 + 1*2 + 2*3) / 5 = 2.0
CPI_2 = (4*1 + 1*2 + 1*3) / 6 = 1.5
功耗墙
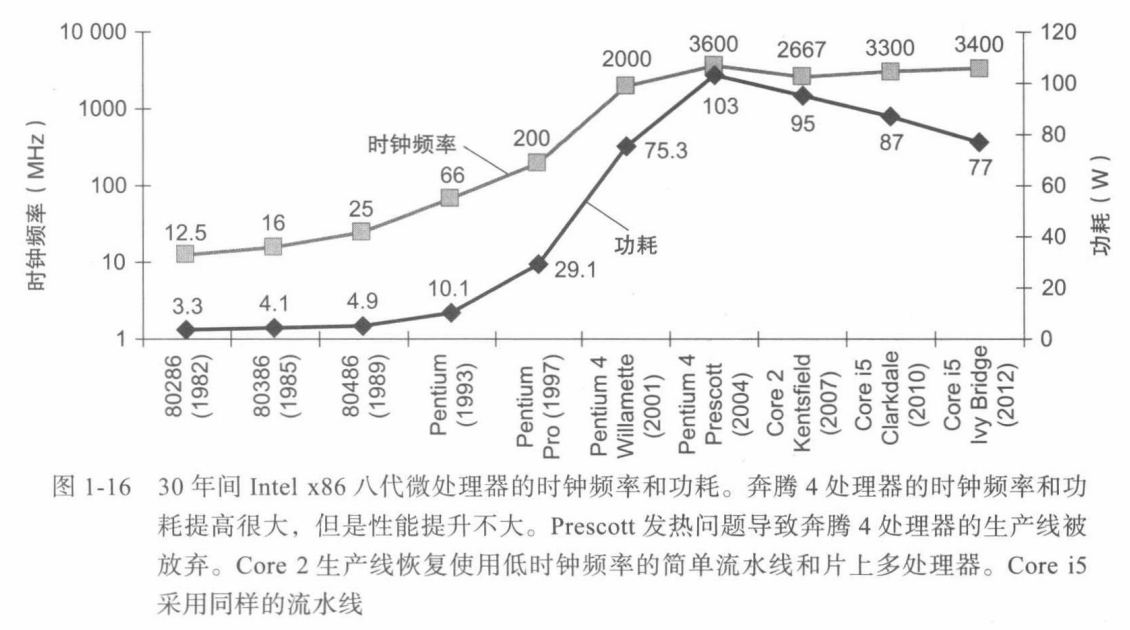
SPEC CPU 基准评测
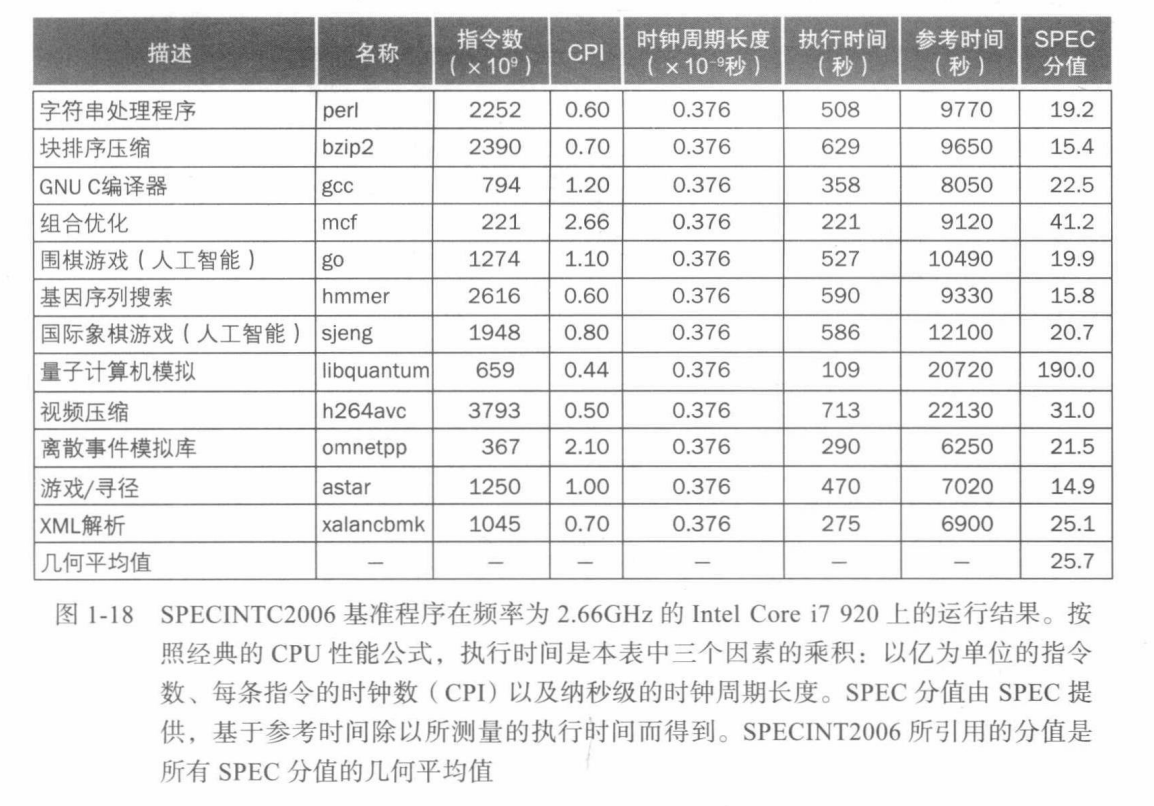
谬误 & 陷阱
- 谬误1:期望总性能与改进大小成正比

- 谬误2
- 谬误3

- 陷阱1

第二章 指令:计算机的语言
指令系统(Instruction Set):给定体系结构理解的命令词汇表。
存储程序:指令与数据不加区别地存储在存储器中并因此易于更改。
指令系统预览
指令系统
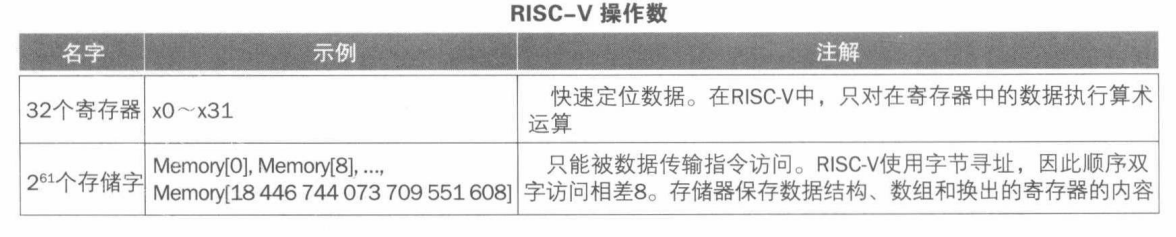
1 操作数
指令操作数(Operand):与高级语言不同,算术指令操作数会受到限制————必须取自寄存器(Register),寄存器数量有限并内建于硬件。
双字(Double Word):一般为 64 位,对应于 RISC-V 中寄存器大小,8个字节。
字(Word):一般为 32 位,4个字节。
寄存器(Register):限制32个。
设计原则2:更少则更快
数量过多的寄存器可能会增加时钟周期,电信号传输的距离越远,所花费的时间越长。
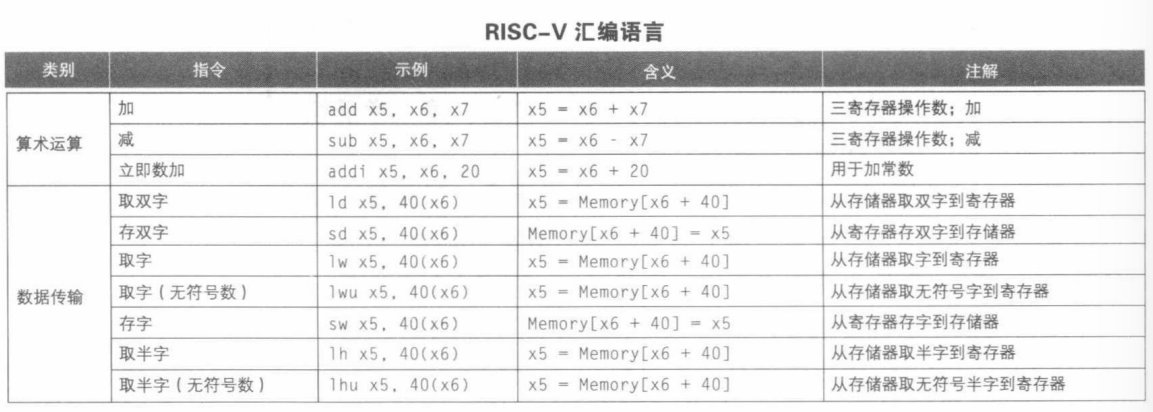
2 数据传输指令
数据传输指令:在内存和寄存器之间传送数据的命令。
地址(Address):用于描述内存数组中特定数据元素位置的值。
载入指令(Load):将数据从内存复制到寄存器。
g = h + A[8];
// x20 <- g
// x21 <- h
// x22 <- address of A[]
编译后:
ld x9, 8(x22) // 临时寄存器 x9 得到 A[8]
add x20, x21, x9 // g = h + A[8]
大小端:
一种使用最左边的“大端”字节作为双字地址,另一种使用最右端或“小端”。RISC-V属于小端编址。
存储指令(Store):将数据从寄存器复制到内存。
A[12] = h + A[8];
// x21 <- h
// x22 <- address of A[]
编译后:
ld x9, 64(x22) // 临时寄存器 x9 得到 A[8]: 64 = 8 * 8bit
add x9, x21, x9 // 临时寄存器 x9 得到 h + A[8]
sd x9, 96(x22) // 存储 h + A[8] 到 A[12]: 96 = 12 * 8bit
3 常数与立即数
通过把常数作为算数指令操作数,操作更快,能耗更低。
常数0有另一个作用:通过有效使用它可以简化指令系统体系结构。例如,你可以使用0寄存器求原数的相反数。因此,RISC-V专用寄存器x0硬连线到常数0。根据使用频率来确定要定义的常数。
求相反数:按位取反加一
4 指令表示
对于 RISC-V 加法指令:x9 = x20 + x21
add x9, x20, x21
指令格式:二进制数字字段组成的指令表示形式。(机器语言)
十进制: | 0 | 21 | 20 | 0 | 9 | 51 |
二进制: | 0000000 | 10101 | 10100 | 000 | 01001 | 0110011 |
位数: 7 + 5 + 5 + 3 + 5 + 7 = 32 bit
段数: [1] [2] [3] [4] [5] [6]
字段:一条指令每一段成为字段,第[1][4][6]字段组合告诉指令执行加法操作,即操作码(Opcode);第[2]告诉加法运算第二个源操作数寄存器编号21;第[3]个字段给出了加法运算的另一个源操作数寄存器编号20;第[5]个字段存放要接收和的寄存器编号9。
RISC-V 指令格式
RISC-V 字段
- 给出 RISC-V (R型)字段命名使其易于讨论:
| funct7 | rs2 | rs1 | funct3 | rd | opcode | [R]
7 5 5 3 5 7
以下是 RISC-V 指令字段信息:
- 操作码(opcode):用于表示该指令操作和指令格式的字段;
- 目的操作数寄存器(rd):用来存放操作结果;
- 附加操作码字段(funct3 & funct7):另外的操作码字段;
- 第一源操作数寄存器(rs1):第一个源操作数;
- 第二源操作数寄存器(rs2):第一个源操作数;
问题:当指令需要两个寄存器和一个常数,则常数通常比31(2^5-1)大得多,5位字段太小。
设计原则3:优秀的设计需要适当的折中
RISC-V 对于不同指令使用不同格式,上述R型格式用于寄存器。另一种为I型,用于带一个常数的算数运算及加载指令。
- I型字段如下:
| immediate | rs1 | funct3 | rd | opcode | [I]
12 5 3 5 7
- 立即数(immediate):为补码值,表示-2^11~2^11-1,用于加载指令时,表示一个字节的偏移量,可相对于基址寄存器
rd偏移2^11(2048)字节; - 对于加载双字指令
ld x9, 64(x22):22存放在rs1,64存放在immediate,9存放在rd。
- S型字段如下:适用于存储双字的指令,需要两个源寄存器(基址和数据)和地址偏移
immediate
| imm[11:5] | rs2 | rs1 | funct3 | imm[4:0] | opcode | [S]
7 5 5 3 5 7
总结
R型指令:
| R | funct7 | rs2 | rs1 | funct3 | rd | opcode | 示例 |
|---|---|---|---|---|---|---|---|
| add | 0000000 | 00011 | 00010 | 000 | 00001 | 0110011 | add x1, x2, x3 |
| sub | 0100000 | 00011 | 00010 | 000 | 00001 | 0110011 | sub x1, x2, x3 |
I型指令:
| I | immediate | rs1 | funct3 | rd | opcode | 示例 |
|---|---|---|---|---|---|---|
| addi | 001111101000 | 00010 | 000 | 00001 | 0110011 | addi x1, x2, x3 |
| ld | 001111101000 | 00010 | 011 | 00001 | 0000011 | ld x1, 1000(x2) |
S型指令:
| S | imm[11:5] | rs2 | rs1 | funct3 | imm[4:0] | opcode | 示例 |
|---|---|---|---|---|---|---|---|
| sd | 0011111 | 00001 | 00010 | 011 | 01000 | 0100011 | sd x1, 1000(x2) |
逻辑操作指令
移位
移位(shift):包括左移、右移、算数右移。
对于立即数的左移逻辑操作slli和右移逻辑操作srli使用I型格式(不适用于对一个64位寄存器移动大于63位操作),假设初始值位于寄存器x19中移位后存入x11,其中immediate字段中只有低6位被实际使用,高6位被用作funct6:
slli x11, x19, 4 ; reg x11 = reg x19 << 4 bits
算术右移srai:不用0填充空出位,用原符号位填充。
三个变体sll,srl,sra从寄存器中取出移位的位数,而不是立即数。
与 或 非
and:两个操作数的逻辑按位操作,只有在两个操作数中的对应位都是1时,结果的对应位才是1。
or:两个操作数的逻辑按位操作,如果两个操作数中的对应位有一个为1,则结果的对应位为1。
not:一个操作数的逻辑按位取反操作,也即是说,把每个1替换为0,把每个0替换为1。
xor:两个操作数的逻辑按位操作,用于计算两个操作数的异或。也就是说,只有两个操作数的对应位不同时,它才会计算为1。
决策指令
if
相等则分支 beq:如果寄存器rs1中值等于寄存器rs2中值,则转移到标签为L1的语句执行。
beq rs1, rs2, L1
不等则分支 bne:如果寄存器rs1中值不等于寄存器rs2中值,则转移到标签为L1的语句执行。
bne rs1, rs2, L1
无条件分支:遇到该指令必须分支。
beq x0, x0, Exit
小于则分支 blt:比较rs1和rs2中值,若rs1较小则跳转。(无符号 bltu)
大等则分支 bge:与上互补。(无符号 bgeu)
ARM 指令系统通过保留额外的位(条件代码或标志位)来表示算术运算结果是否溢出等等。
有符号数 -> 无符号数能简便检查数组越界:二进制补码中负整数强转为无符号为很大的数。
begu x20, x11, IndexOutOfBounds
; if x20 > x11 or x20 < 0 goto IndexOutOfBounds
while
对于一个C语言常见循环:
while (save[i] == k)
i += 1;
// x22 <- i
// x24 <- k
// x25 <- save[]
汇编如下:
Loop:
slli x10, x22, 3 ; reg x10 = i * 8
add x10, x10, x25 ; reg x10 = save[]
ld x9, 0(x10) ; reg x9 = save[]
bne x9, x24, Exit ; if save[] != k goto Exit
addi x22, x22, 1 ; i = i + 1
beq x0, x0, Loop ; goto Loop
Exit:
case & switch
两种实现:
- 转换为
if then else; - 使用分支地址表:程序索引到表内,并跳转到其他指令序列(双字数组,包含与代码中标签对应的地址)。程序将分支表内相应条目加载到寄存器中,需要使用寄存器中地址进行跳转。
间接跳转指令:对寄存器中指定地址执行无条件跳转。(如跳转-链接指令jalr)
寄存器与堆栈
过程调用
过程(Procedure):一个根据给定参数执行特定任务的已存储的子程序。
过程允许程序员一次只专注任务的一部分,参数可以传递数值并返回结果。在执行过程时,程序遵循以下六步:
- 将参数放在过程可以访问到的位置;
- 将控制转交给过程;
- 获取过程所需的存储资源;
- 执行所需任务;
- 将结果放在调用程序可以访问到的位置;
- 将控制返回到初始点,因为过程可以从程序中多个点调用。
寄存器
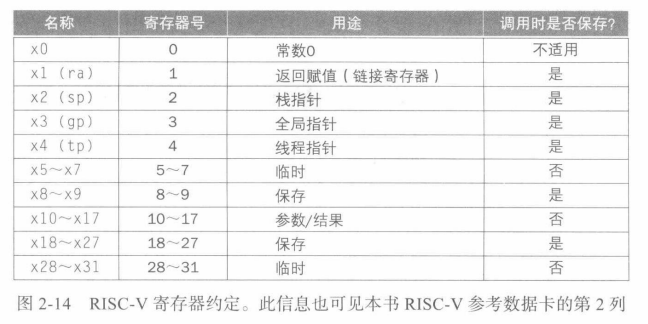
寄存器时访问数据最快的位置,期望尽可能多的使用它。RISC-V 为过程调用分配寄存器如下:
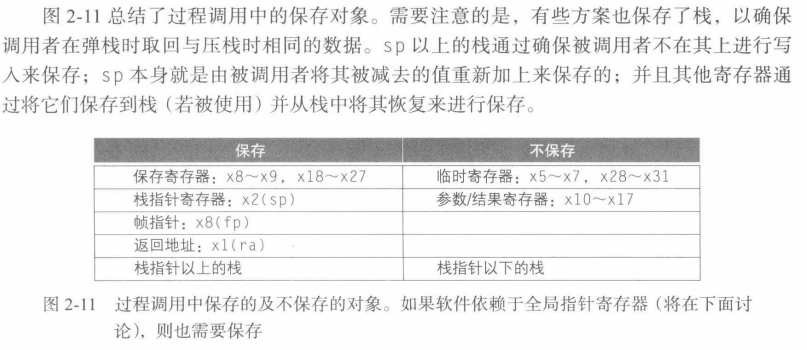
x10 ~ x17:8个参数寄存器,用于传参和返回;x1:一个返回地址寄存器,用于返回到起始点;x5 ~ x7 && x28 ~ x31:临时寄存器,不被被调用的过程保存;x8 ~x9 && x18 ~ x27:保存寄存器,在过程调用中必须被保存。- RISC-V 还包括一个用于过程的跳转-链接指令
jal:跳转到某个地址的同时将下一条指令保存到目标寄存器rd(通常为x1)。
jal x1, ProcedureAddr
假如:对于一个过程,编译器需要比8个参数寄存器更多的寄存器,调用者所需的所有寄存器需要换出到存储器内,其理想结构为栈(stack)。
栈 stack
栈(stack)是一种后进先出的队列。栈需要一个指向栈中最新分配地址的指针,来指示将寄存器值换出的位置。在 RISC-V 中,栈指针(stack point)时寄存器x2,也称sp。
- 压栈:放入数据;
- 弹栈:移除数据;
- 地址顺序:从高地址向低地址增长。
现在要编译一个C过程体:
long long int lead_example (long long int g,
long long int h,
long long int i,
long long int j)
{
long long int f;
f = (g + h) - (i + j);
return f;
}
// x10 <- g
// x11 <- h
// x12 <- i
// x13 <- j
// x20 <- f
编译后:
leaf_example:
addi sp, sp, -24 ; 栈创建 3 个双字空间: 3 * 8 = 24 Byte
sd x5, 16(sp) ; 保存临时寄存器 x5 的值到栈
sd x6, 8(sp) ; 保存临时寄存器 x6 的值到栈
sd x20, 0(sp) ; 保存临时寄存器 x20 的值到栈
; 以下三条语句对应过程体
add x5, x10, x11 ; reg x5 = g + h
add x6, x12, x13 ; reg x6 = i + j
add x20, x5, x6 ; f = reg x20 = x5 - x6
; 为了返回 f 值,将其复制到一个参数寄存器中
addi x10, x20, 0 ; 返回: reg x10 = f + 0
; 返回之前,通过栈中弹出数据恢复寄存器三个旧值
ld x20, 0(sp) ; 从栈中取出寄存器的值 reg x20 = sp[0]
ld x6, 8(sp) ; 从栈中取出寄存器的值 reg x6 = sp[1]
ld x5, 16(sp) ; 从栈中取出寄存器的值 reg x5 = sp[2]
addi sp, sp, 24 ; 栈释放 3 个双字空间
jalr x0, 0(x1) ; 分支返回 x1 起始点
在上述例子中,由于调用者不希望在过程中保存寄存器
x5和x6,可以在代码中去掉两次存储和载入。
嵌套
不调用其他过程的过程称为叶子过程(Leaf Procedure)。如果调用自己时,同样的寄存器会有使用冲突,一个解决方法时将其他所有必须保存的寄存器压栈。调整栈指针sp以计算压栈寄存器的数量,返回时从寄存器中恢复寄存器并重新调整栈指针。
现在要编译一个递归的C过程:
long long int fact (long long int n)
{
if (n < 1) return (1);
else return (n * fact(n - 1));
}
// x10 <- n
// x0 <- 0
编译后:
fact:
addi sp, sp, -16 ; 栈创建 2 个双字空间: 2 * 8 = 16 Byte
sd x1, 8(sp) ; 保存临时寄存器 x1 = old_addr 的值到栈
sd x10, 0(sp) ; 保存 x10 = n 到栈
; 第一次调用 fact 时,sd 保存程序中调用 fact 的地址
; 下面两条指令测试 n 是否小于 1 ,如果 n >= 1 则跳转到 L1
addi x5, x10, -1 ; reg x5 = n - 1
bge x5, x0, L1 ; if (n - 1) >= 0 goto L1
; 如果 n < 1,fact 将 1 放入一个值寄存器并返回 1,即 fact(1)
addi x10, x0, 1 ; reg x10 = 0 + 1
addi sp, sp, 16 ; 释放栈指针空间
jalr x0, 0(x1) ; 分支返回 x1 起始点
L1:
addi x10, x10, -1 ; 如果 n >= 1, reg x10 = n - 1
jal x1, fact ; 使用 x10 的值调用 fact(n - 1), x1 = new_addr
addi x6, x10, 0 ; reg x6 = fact(n - 1)
ld x10, 0(sp) ; 从栈中取出寄存器的值 reg x10 = sp[0] = n
ld x1, 8(sp) ; 从栈中取出寄存器的值 reg x1 = sp[1] = old_addr
addi sp, sp, 16 ; 栈删除 2 个双字空间
mul x10, x10, x6 ; reg x10 = n * fact(n - 1)
jalr x0, 0(x1) ; 分支返回 x1 起始点
为了简化静态数据的访问,一些 RISC-V 编译器保留一个寄存器x3用作全局指针(Global Pointer)或者gp:指向静态数据区的保存寄存器。
栈同时也用于存储过程的局部变量,但这些变量不适用于寄存器(如:局部数组或结构体)。栈中包含过程所保存的寄存器值和局部变量的段称为过程帧或活动记录,图中展示了过程调用前、调用期间、调用后的栈状态。
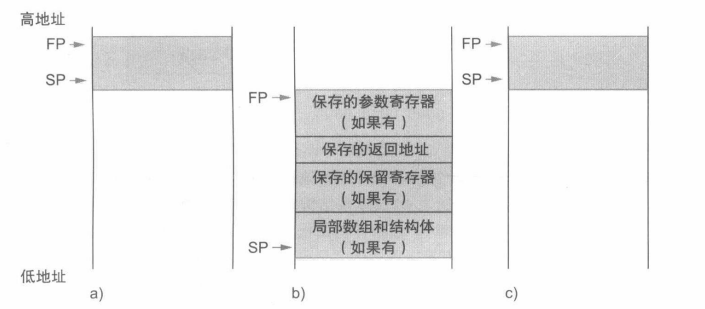
一些 RISC-V 编译器使用帧指针fp或者寄存器x8来指向过程帧的第一个双字。
堆 heap
图中展示了 Linux OS 内存空间分配约定:
- 栈(stack):存储寄存器和局部变量,从用户地址空间高地址向下拓展;
- 堆(heap):存储动态数据(数组和链表);
- 静态数据段(static data segment):存储常量和其他静态变量;
- 代码段(text segment):存储执行代码;
- 保留段:保留的存储空间。
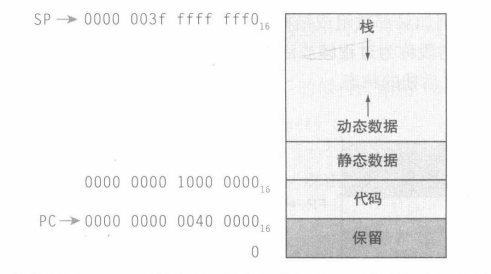
内存泄漏:
C通过显示函数调用来分配和释放堆上的内存,
malloc分配,free释放;忘记释放空间会导致内存泄露,最终耗尽大量内存;过早释放空间会导致悬空指针,会导致指针乱指。
RISC-V 寄存器约定:
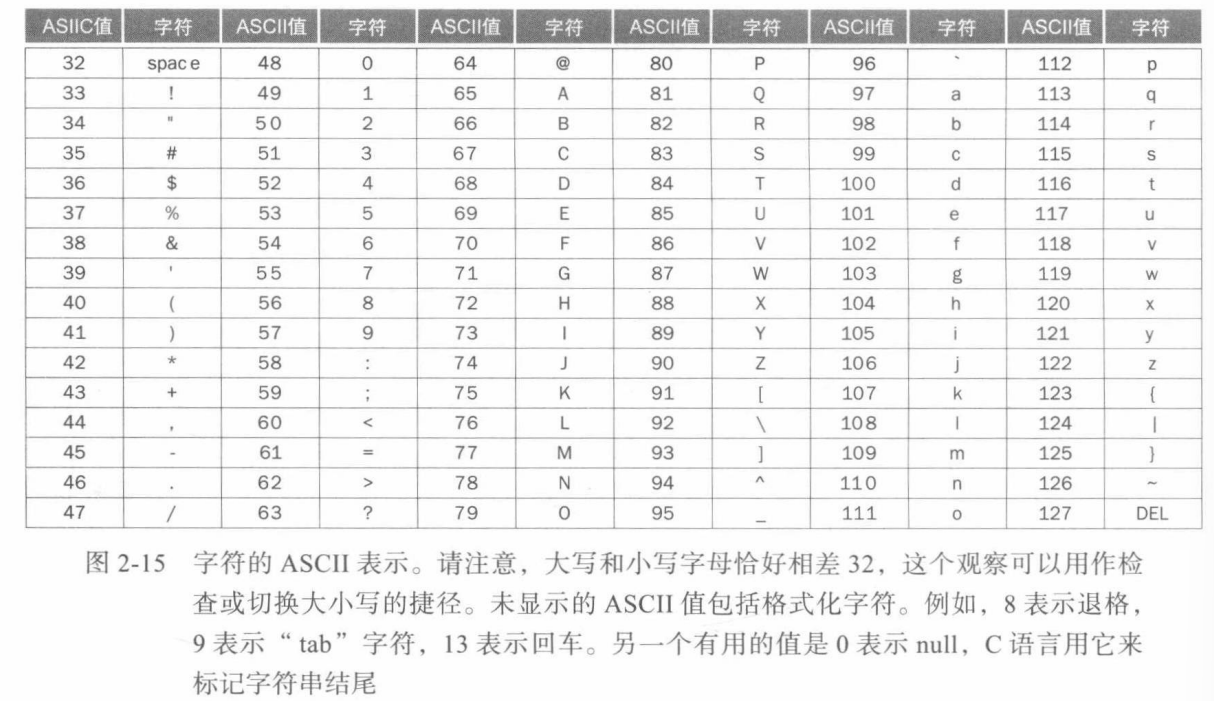
ASCII 人机交互
ASCII(American Standard Code for Information Interchange)是每个人用来遵循的字符表示方法:
字节转移指令
加载无符号字节指令lbu:从内存中加载一个字节,将其放在寄存器最右边8位。
存储字节指令sb:从寄存器的最右边8位取一个字节将其写入内存。
复制一个字节的顺序如下:
lbu x12, 0(x10) ; 读取源字节 0(x10) 到寄存器 x12
sb x12, 0(x11) ; 写入字节 x12 到内存 0(x11) 中
字符串通常有三种表示:
- 字符串第一个位置保留,用于给出字符串长度;
- 附加带有字符串长度的变量(如结构体);
- 字符串最后位置用一个字符标记结尾。
C语言使用第三种选择,使用值为 0 的字节表示终止字符串(ASCII中命名为null)。因此,字符串Cal一般用67 97 108 0来表示。
接下来要编译一个字符串复制程序:将字符串y复制到字符串x
void strcpy (char x[], char y[])
{
size_t i;
i = 0;
while ((x[i] = y[i]) != '\0')
i += 1;
}
// x10 <- x[]
// x11 <- y[]
// x19 <- i
编译后的 RISC-V 汇编代码如下:
strcpy:
addi sp, sp, -8 ; 栈申请 1 Byte 空间
sd x19, 0(sp) ; 将 x19 的值压栈
add x19, x0, x0 ; i = reg x19 = 0 + 0
; 循环开始
L1:
add x5, x19, x11 ; reg x5 = addr of y[i]
lbu x6, 0(x5) ; reg x6 <- y[i]
add x7, x19, x10 ; reg x7 = addr of x[i]
sb x6, 0(x7) ; x[i] <- reg x6 = y[i]
beq x6, x0, L2 ; if y[i] = 0 goto L2
; if y[i] != 0 continue
addi x19, x19, i ; i = i + 1
jal x0, L1 ; goto L1
L2:
ld x19, 0(sp) ; 弹栈到 x19
addi sp, sp, 8 ; 栈释放 1 Byte 空间
jalr x0, 0(x1) ; return
Unicode
Unicode 是大多数人类语言中字母表的通用编码,16位半字。
RISC-V 具有加载存储半字的指令:
lhu x19, 0(x10) ; reg x19 <- 0(x10)
sh x19, 0(x11) ; 0(x11) <- x19
大立即数编址寻址
虽然将 RISC-V 指令保持32bit可以简化硬件,但有时使用更大的地址会很方便。
大立即数
RISC-V 指令系统包括取立即数高位指令lui(取立即数高位),用于将20位常数加载到寄存器的第31位到第12位,将31位的值复制填充到左边31位。最右边的12位用0填充。其使用新的指令格式U型(其他格式不支持如此大的常量)。
将以下64bit常量加载到寄存器x19:
00000000 00000000 00000000 00000000 00000000 00111101 00000101 00000000
首先使用lui加载12到31位,十进制数
深入了解计算机系统
超标量处理器设计
Linux 常用命令
grep & sed & awk
参考资料:
功能简介
grep- 用于查找sed- 取行 & 替换awk- 取列
正则表达式
三剑客是工具,正则表达式是模板,三剑客可以读懂这个模板。
正则表达式(Regular Expression):由一些普通字符(Common Character)和一些元字符(Meta Character)组成。
其中,普通字符包括大小写数字和字母。而元字符具有特殊含义:
| 元字符 | 功能 | 解释 |
|---|---|---|
| ^ | 匹配行首 | 表示以某个字符开头 |
| $ | 匹配行尾 | 表示以某个字符结尾 |
| ^$ | 空行 | 表示空行 |
| . | 匹配任意单个字符 | 表示任意一个字符 |
| * | 匹配0个或多个该字符 | 表示匹配重复字符 |
| \ | 屏蔽元字符功能 | 表示去除元字符功能,直接显示 |
| [] | 匹配括号内字符 | 表示过滤括号内的字符 |
| .* | 匹配任意多个字符 | 表示任意多个字符 |
| expr{n} | 匹配expr出现次数 | n为次数 |
| expr{n,} | 同上,但最少次数为n | n为次数 |
| expr{n,m} | 同上,但次数在n,m之间 | n为次数 |
grep
文本过滤工具:grep, egrep,使用方法:
grep [OPTIONS] PATTERN [FILE...]
--color=auto 对匹配到的文本着色显示
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系
grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 相当于fgrep,不支持正则表达式
- 查找文件内包含
apple字符串的行号:
grep -n apple FILE
- 查找文件内容不包含
apple的行号:
grep -nv apple FILE
- 查找以
a开头的行:
grep ^a FILE
- 查找以
e结尾的行:
grep e$ FILE
- 通过管道运算符
|,和其他程序一起使用:
cat FILE | grep apple
sed
流编辑器,一次处理一行。使用方法:
处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如
D的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
sed [option]... 'script' inputfile
[选项]
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f /PATH/SCRIPT_FILE: 从指定文件中读取编辑脚本
-r 支持使用扩展正则表达式
-i 直接编辑文件
-i.bak 备份文件并原处编辑
[script 地址定界]
不给地址:对全文进行处理
单地址:
#: 指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
地址范围:
#,#
#,+#
/pat1/,/pat2/
`#,/pat1/
~:步进
1~2 奇数行
2~2 偶数行
[编辑命令]
d 删除模式空间匹配的行,并立即启用下一轮循环
p 打印当前模式空间内容,追加到默认输出之后
a [\]text1 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本
w /path/somefile 保存模式匹配的行至指定文件
r /path/somefile 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
s///:查找替换,支持使用其它分隔符,s@@@,s###
替换标记
g 行内全局替换
p 显示替换成功的行
w /PATH/TO/SOMEFILE 将替换成功的行保存至文件中
二进制翻译
二进制翻译(Binary Translation)的定义:
目录
端到端翻译
Cache 优化
软硬件结合
动静结合
hybitor
项目地址:Github | hybitor - 一个混合翻译器
ELF 文件加载解析
参考资料:
程序内存布局
将源码(source code)编译为 ELF 文件后,其变成一个看似充满杂乱无章字节的文件。但可以将其分为程序(Program)和数据(Data)两部分:
- 程序:由一条条能被解码(Decode)的指令组成;
- 数据:存放着被程序控制读写的数据;
事实上,还能将文件划分为更小的单位:段(Section)。不同的段被放置在内存不同的位置上,这构成了程序的内存布局(Memory Layout),一种典型的程序相对内存布局如下:
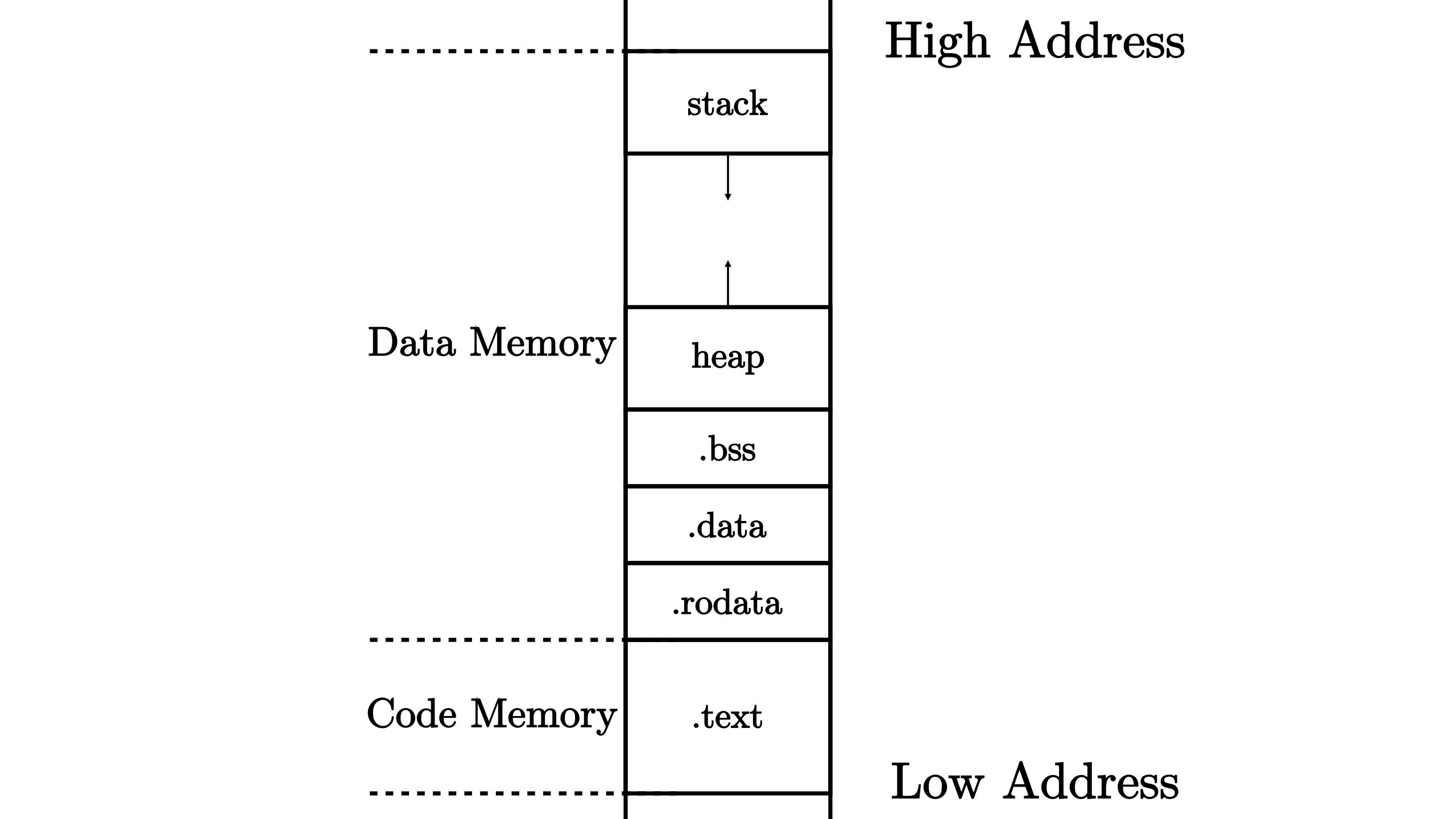
代码段:.text(存放所有程序)
数据段:
.rodata:(已初始化)只读的全局数据,常数、常量字符串;.data:(已初始化)可修改的全局数据;.bss:(未初始化/初始化为0)全局&静态数据,由程序加载器(Loader)代为清零;- 堆(heap):用来存放程序运行时动态分配的数据,向高地址增长,如:
new,melloc; - 栈(stack):用作函数调用上下文保存与恢复,每个函数的局部变量被编译器放于栈帧,向低地址增长。
函数视角上,能访问的变量:
- 函数入参和局部变量:保存在寄存器或函数栈帧内;
- 全局变量:保存在
.data和.bss,通过寄存器gp(x3)+offset来访问- 堆上的动态变量:运行时分配指针来访问,该指针可作为局部变量(栈帧)也可作为全局变量。
编译流程
编译主要有三个流程:
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
链接器所做的事情是将所有输入的目标文件整合成一个整体的内存布局。在此期间链接器主要完成两件事情:
- 将来自不同目标文件的段在目标内存布局中重新排布。如下图所示,在链接过程中,分别来自于目标文件
1.o和2.o段被按照段的功能进行分类,相同功能的段被排在一起放在拼装后的目标文件output.o中。注意到,目标文件1.o和2.o的内存布局是存在冲突的,同一个地址在不同的内存布局中存放不同的内容。而在合并后的内存布局中,这些冲突被消除; - 将符号替换为具体地址。
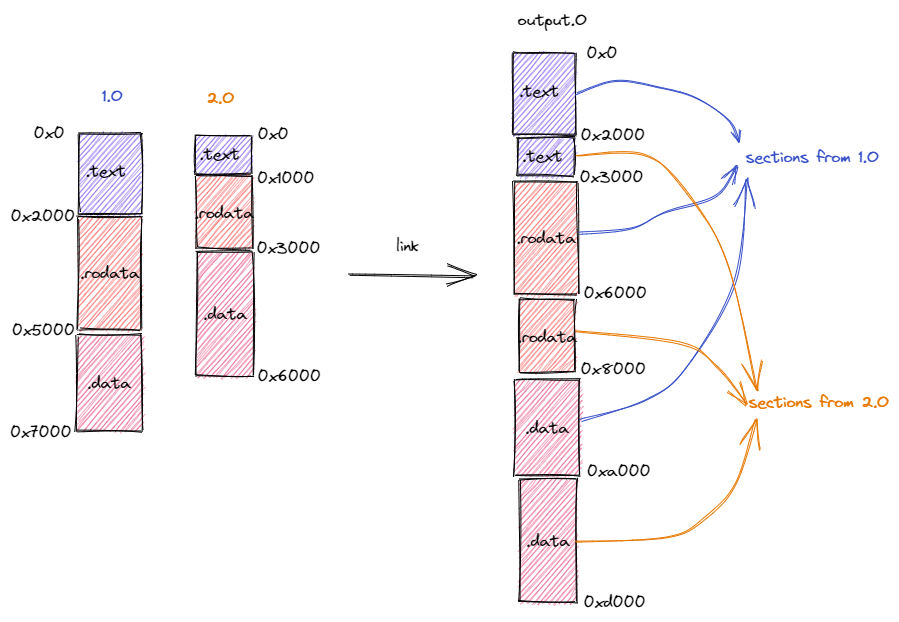
备注:
- 这里的符号(Symbol)指什么呢?
我们知道,在我们进行模块化编程的时候,每个模块都会提供一些向其他模块公开的全局变量、函数等供其他模块访问,也会访问其他模块向它公开的内容。要访问一个变量或者调用一个函数,在源代码级别我们只需知道它们的名字即可,这些名字被我们称为符号。取决于符号来自于模块内部还是其他模块,我们还可以进一步将符号分成内部符号和外部符号。
然而,在机器码级别(也即在目标文件或可执行文件中)我们并不是通过符号来找到索引我们想要访问的变量或函数,而是直接通过变量或函数的地址。例如,如果想调用一个函数,那么在指令的机器码中我们可以找到函数入口的绝对地址或者相对于当前 PC 的相对地址。
- 那么,符号何时被替换为具体地址呢?
因为符号对应的变量或函数都是放在某个段里面的固定位置(如全局变量往往放在
.bss或者.data段中,而函数则放在.text段中),所以我们需要等待符号所在的段确定了它们在内存布局中的位置之后才能知道它们确切的地址。当一个模块被转化为目标文件之后,它的内部符号就已经在目标文件中被转化为具体的地址了,因为目标文件给出了模块的内存布局,也就意味着模块内的各个段的位置已经被确定了。**然而,此时模块所用到的外部符号的地址无法确定。**我们需要将这些外部符号记录下来,放在目标文件一个名为符号表(Symbol table)的区域内。由于后续可能还需要重定位,内部符号也同样需要被记录在符号表中。
外部符号需要等到链接的时候才能被转化为具体地址。假设模块 1 用到了模块 2 提供的内容,当两个模块的目标文件链接到一起的时候,它们的内存布局会被合并,也就意味着两个模块的各个段的位置均被确定下来。此时,模块 1 用到的来自模块 2 的外部符号可以被转化为具体地址。
同时我们还需要注意:两个模块的段在合并后的内存布局中被重新排布,其最终的位置有可能和它们在模块自身的局部内存布局中的位置相比已经发生了变化。因此,每个模块的内部符号的地址也有可能会发生变化,我们也需要进行修正。上面的过程被称为重定位(Relocation)。
这个过程形象一些来说很像拼图:由于模块 1 用到了模块 2 的内容,因此二者分别相当于一块凹进和凸出一部分的拼图,正因如此我们可以将它们无缝地拼接到一起。
ELF 文件视图
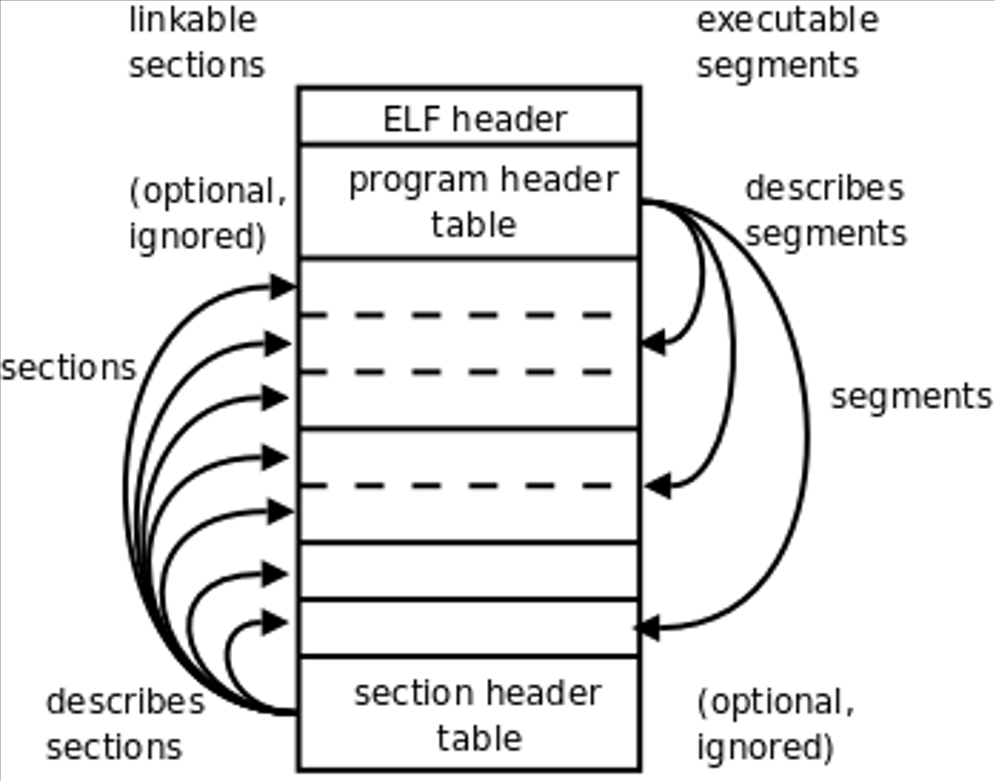
一个 ELF 可执行文件可以通过两个视图去分析:
- 链接视图(Link View):以节(Section)为单位;
- 执行视图(Exec View):以段(Segment)为单位;
ELF 头信息(ELF header)
ELF文件的最开始是ELF文件头(ELF Header):包含了描述整个文件的基本属性。ELF文件分为文件头和文件体两部分:
- 先用 ELF header 从文件全局概要出程序中程序头表(phdr)、节头表(shdr)的位置和大小等信息;
- 然后从程序头表和节头表中分别解析出各个段和节的位置和大小等信息;
typedef struct elf64_hdr {
unsigned char e_ident[EI_NIDENT];
Elf64_Half e_type; // 文件类型
Elf64_Half e_machine; // 体系结构
Elf64_Word e_version; // 版本信息
Elf64_Addr e_entry; // 虚拟地址入口
Elf64_Off e_phoff; // phdr在文件内偏移量
Elf64_Off e_shoff; // shdr在文件内偏移量
Elf64_Word e_flags; // 处理器相关标志
Elf64_Half e_ehsize; // elf header大小
Elf64_Half e_phentsize; // phdr大小
Elf64_Half e_phnum; // 段个数
Elf64_Half e_shentsize; // shdr大小
Elf64_Half e_shnum; // 节个数
Elf64_Half e_shstrndx;
} Elf64_Ehdr;
e_ident[EI_NIDENT]是16字节大小的数组,用来表示ELF字符等信息,开头四个字节是固定不变的elf文件魔数(Magic Number):
e_ident[0..3] = 0x7fELF // 魔数
e_ident[4] // 位数:1(32bit), 2(64bit)
e_ident[5] // 大小端:1(LSB), 2(MSB)
e_ident[6] // 版本
e_ident[7-15] // 保留位
e_type(2字节)指定了文件类型:
// include/uapi/linux/elf.h
#define ET_NONE 0 // 未知目标文件格式
#define ET_REL 1 // 可重定位文件
#define ET_EXEC 2 // 可执行文件
#define ET_DYN 3 // 动态共享目标文件
#define ET_CORE 4 // core文件,程序崩溃时内存映像的转储格式
#define ET_LOPROC 0xff00 // 特定处理器文件的扩展下界
#define ET_HIPROC 0xffff // 特定处理器文件的扩展上界
e_machine(2字节):描述目标文件体系结构:
// include/uapi/linux/elf-em.h
#define EM_NONE 0
#define EM_M32 1
#define EM_SPARC 2
#define EM_386 3
#define EM_68K 4
#define EM_88K 5
#define EM_486 6 /* Perhaps disused */
#define EM_860 7
#define EM_MIPS 8 /* MIPS R3000 (officially, big-endian only) */
/* Next two are historical and binaries and
modules of these types will be rejected by
Linux. */
#define EM_MIPS_RS3_LE 10 /* MIPS R3000 little-endian */
#define EM_MIPS_RS4_BE 10 /* MIPS R4000 big-endian */
#define EM_PARISC 15 /* HPPA */
#define EM_SPARC32PLUS 18 /* Sun's "v8plus" */
#define EM_PPC 20 /* PowerPC */
......
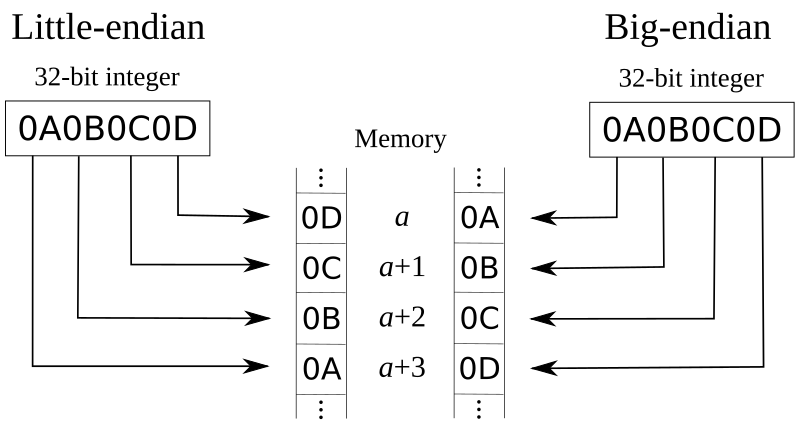
端序或尾序(Endianness),又称字节顺序。在计算机科学领域中,指电脑内存中或在数字通信链路中,多字节组成的字(Word)的字节(Byte)的排列顺序。字节的排列方式有两个通用规则:例如,将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序(little-endian);反之则称大端序(big-endian)。常见的 x86、RISC-V 等架构采用的是小端序。
程序头表(phdr)
程序头表(也称为段表)是一个描述文件中各个段的数组,程序头表描述了文件中各个段在文件中的偏移位置及段的属性等信息;从程序头表里可以得到每个段的所有信息,包括代码段和数据段等:
typedef struct elf64_phdr {
Elf64_Word p_type; // 程序段类型
Elf64_Word p_flags; // 本段相关标志
Elf64_Off p_offset; // 本段在文件内起始偏移
Elf64_Addr p_vaddr; // 本段在内存中虚拟地址
Elf64_Addr p_paddr; // 本段在内存中物理地址
Elf64_Xword p_filesz; // 段在文件中大小
Elf64_Xword p_memsz; // 段在内存中大小
Elf64_Xword p_align; // 本段的对齐方式
} Elf64_Phdr;
对于p_type(4字节):指明段类型
// include/uapi/linux/elf.h
#define PT_NULL 0 // 忽略
#define PT_LOAD 1 // 可加载程序段
#define PT_DYNAMIC 2 // 动态链接信息
#define PT_INTERP 3 // 动态加载器名称
#define PT_NOTE 4 // 辅助的附加信息
#define PT_SHLIB 5 // 保留
#define PT_PHDR 6 // 程序头表
#define PT_TLS 7 /* Thread local storage segment */
#define PT_LOOS 0x60000000 /* OS-specific */
#define PT_HIOS 0x6fffffff /* OS-specific */
#define PT_LOPROC 0x70000000
#define PT_HIPROC 0x7fffffff
对于p_flag(4字节):指明段标志
// include/uapi/linux/elf.h
#define PF_R 0x4 // 可读
#define PF_W 0x2 // 可写
#define PF_X 0x1 // 可执行
ELF 文件装载执行
参考资料:
静态库加载(Static Lib Load)
这里说的静态库加载指的是程序链接到静态库生成的exe文件的加载,静态库的加载相对动态库要简单很多,因为全部工作已经由编译器的链接器ld给我们完成了,我们要做的只是把ELF文件map到相应运行地址空间,然后把PC指向entry即可。
- 数据映射(Data Map):可以理解为copy,因为每一个 elf 都具有相同运行的地址空间,这个可以通过链接脚本指定,上面的 elf 的运行地址空间从
0x80000000开始,很明显这个地址是个虚拟地址,也就是说,我们要把 elf 文件映射到这个地址空间上去; - 究竟拷贝哪些内容呢?我们之前的 segment 现在可以出马了,segment 里记录了我们需要拷贝的内容的全部信息。在静态库加载中,我们直接把属性为 RWE 的 LOAD 段拷贝到
0x80000000,即可,需要注意的是,需要手动把.bss清0; - 将PC指向之前解析的 elf header 中的
e_entry。
注意:在多个ELF加载的过程中,需要把相同运行地址空间映射到不同的物理地址空间,这样才能保证每个ELF的代码和数据是相互独立的。(这个概念和多进程有点类似,此处不多讲,这涉及到地址空间管理的问题)
动态库加载(Dynamic Lib Load)
内存管理
内存地址对齐(Memory Address Align)是内存中的数据排列及 CPU 访问内存数据的方式,包含了基本数据对齐和结构体数据对齐的两部分。
CPU 在内存中读写数据是按字节块进行操作,理论上任意类型的变量访问可以从内存的任何地址开始,但在计算机系统中,CPU 访问内存是通过数据总线(决定了每次读取的数据位数)和地址总线(决定了寻址范围)来进行的,基于计算机的物理组成和性能需求,CPU 一般会要求访问内存数据的首地址的值为 4 或 8 的整数倍。
基本类型数据对齐(Basic Type Data Align)是指数据在内存中的偏移地址必须为一个字的整数倍,这种存储数据的方式,可以提升系统在读取数据时的性能。结构体数据对齐,是指在结构体中的上一个数据域结束和下一个数据域开始的地方填充一些无用的字节,以保证每个数据域(假定是基本类型数据)都能够对齐(即按基本类型数据对齐)。
对于 RISC-V 处理器而言,load/store 指令进行数据访存时,数据在内存中的地址应该对齐。如果访存 32 位数据,内存地址应当按 32 位(4字节)对齐。如果数据的地址没有对齐,执行访存操作将产生异常。这也是在学习内核编程中经常碰到的一种 bug。
Perf 安装
参考资料:
Linux 安装 perf
- 在线安装
perf,先获取Linux内核源码:
sudo apt-get update
sudo apt-get install linux-tools-common
- 安装
linux-tools获取perf:
sudo apt-get install linux-tools-$(uname -r)
- 安装完毕后,可以使用
perf stat命令来进行性能分析。例如:查看ls命令 CPU 使用情况:
sudo perf stat ls
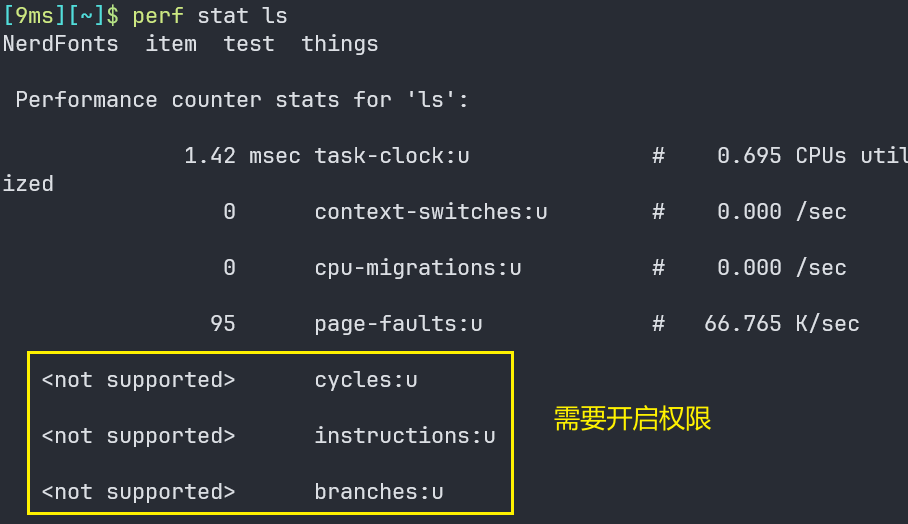
perf 开启权限
- 使用
perf时部分性能指标未开启:
- 修改
sudo vim /etc/sysctl.conf:
kernel.perf_event_paranoid = -1
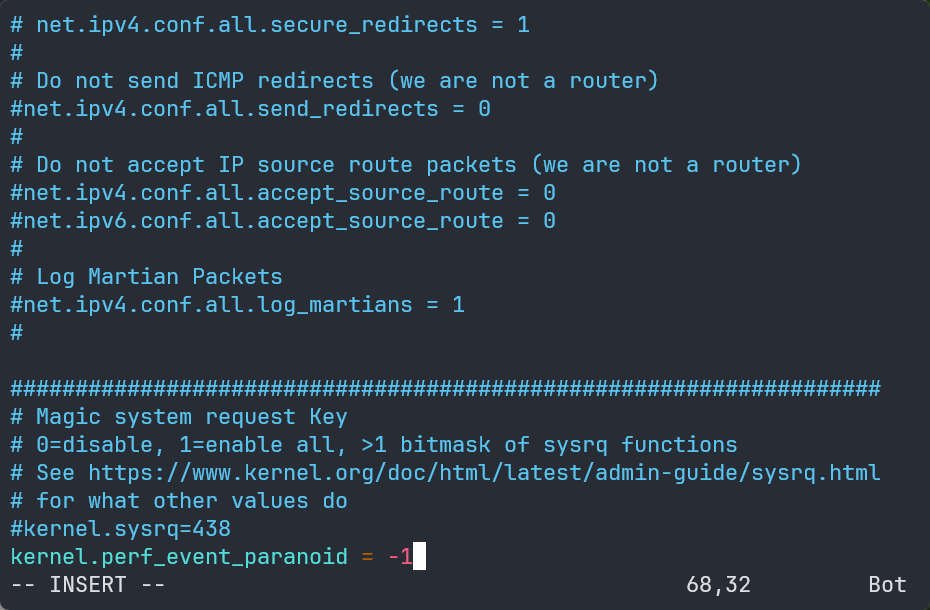
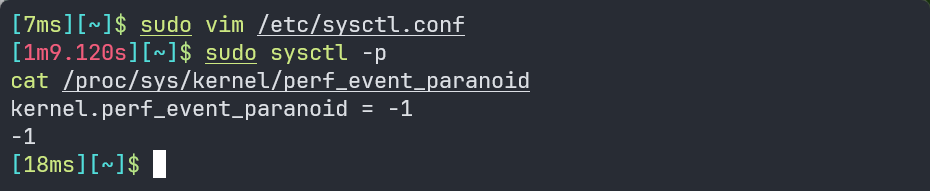
sudo sysctl -p更新配置文件,查看更新后的值判断是否为-1:
sudo sysctl -p
cat /proc/sys/kernel/perf_event_paranoid
Vmware 中的 perf 问题
虚拟机中perf stat如果无法测量cycles和branches,有如下可能:
-
这一款cpu不支持虚拟计数器(例如:13代 Intel
VMPC启动失败); -
cpu支持虚拟计数器,但虚拟机未开启功能,关闭VMware虚拟机电源,找到硬件配置选项中CPU勾选:虚拟化cpu性能计数器,重启虚拟机。
WSL2 下安装 perf
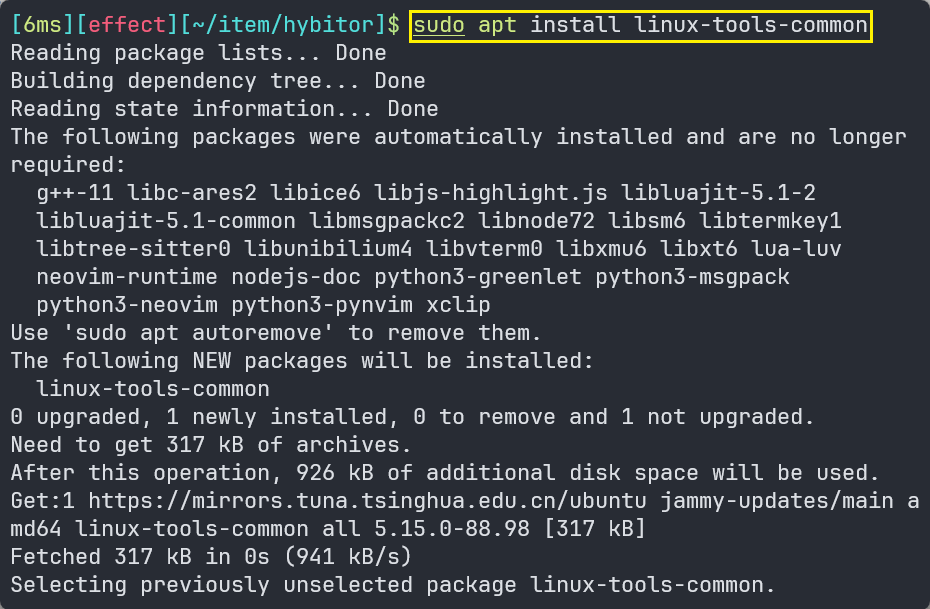
- 安装Linux实用工具:
sudo apt install linux-tools-common
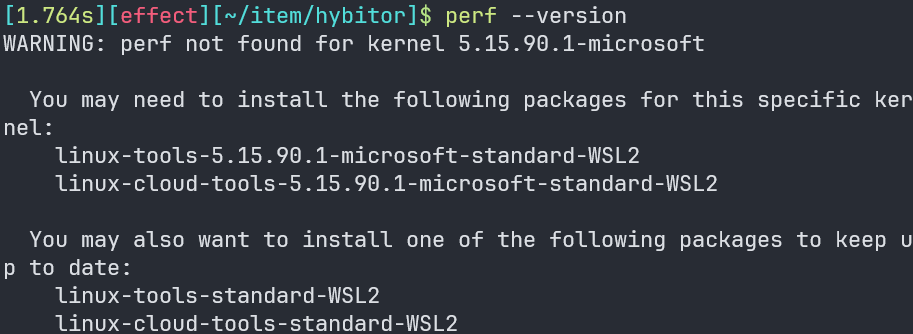
- 查看perf版本:
perf --verison
- 安装依赖:
sudo apt install flex bison
- 下载WSL2内核并编译,复制编译好的perf程序:
git clone https://github.com/microsoft/WSL2-Linux-Kernel --depth 1
cd WSL2-Linux-Kernel/tools/perf
make -j8
sudo cp perf /usr/local/bin
eBPF 简介
参考链接 :
1 eBPF 是什么

eBPF (Extended Berkeley Packet Filter)是可以在内核虚拟机中运行的程序,不需要更改内核源码或加载内核模块,动态安全的拓展内核功能。
- eBPF 是一个:内核虚拟机、运行时沙盒、受限编程语言;
- eBPF 之于 Linux Kernel,相当于 JS 之于 Web;
- eBPF 是在 BPF 基础上的拓展增强;
.png)
关于 BPF :
是伯克利包过滤(Berkeley Packet Filter)的简写;
BPF现在一般叫做 cBPF(Classic BPF),eBPF 现在一般叫做 BPF ;
允许 User 程序链接到网络套接字,进行过滤筛选;
网络抓包工具:
tcpdump和wireshark就是 cBPF 的经典案例;eBPF现在被认为是一个独立的术语,与 cBPF 关系不大。
2 eBPF 能做什么
应用领域:
- 网络:在现代数据中心和云原生环境中提供高性能网络和负载平衡;
- 安全:以低开销提取细粒度的安全可观测性数据;
- 性能监测:跟踪应用程序、排障,监测程序或容器运行时;
- 可视化:可视化内核相关事件指标。
2.1 事件 Events
- 数据源(Data Source):提供数据的来源。
- 事件(Events):数据源产生数据的一系列行为。
.png)
2.2 追踪 Tracing
- Tracing 内核框架:负责对接数据源,采集解析发送数据,对用户态提供接口。
- Tracing 前端工具:对接 Tracing 内核框架,直接与用户交互,负责数据采集、配置、数据。
.png)
2.3 数据源探针
2.3.1 硬件探针
- 硬件探针(HPC, Hardware Performance Counter):是CPU硬件提供的功能,它能够监控CPU级别的事件,比如执行的指令数,跳转指令数,Cache Miss等等,被广泛用于性能调试(Vtune, Perf)、攻击监测等等。
.png)
perf stat使用 HPC 采集数据:
.png)
- LBR(Last Branch Record)是硬件提供的另一种特性,能够::记录每条分支(跳转)指令的源地址和目的地址::。基于LBR硬件特性,可实现调用栈信息记录。基于 LBR 特性可生成火焰图(Flame Graph)。
.png)
备注:使用
perf record -F 99 -a --call-graph lbr收集数据,火焰图与用户之间有较大的语义鸿沟。
.png)
2.3.2 软件探针对比
- 通过静态探针(tracepoint: sched_process_exec)监控进程执行二进制文件的行为:
.png)
- 通过动态探针(kprobe: exec_binprm)监控进程执行二进制文件的行为:
.png)
- 另一个终端上的输入:
.png)
- 对比:::eBPF尝试结合两者优势::
| 静态探针 | 动态探针 | |
|---|---|---|
| 代表 | Kernel Tracepoint | Kprobe |
| 性能 | 好 | 相对较差 |
| 稳定性 | 稳定 | 不稳定(函数变更可能导致程序失效) |
| 修改内核代码 | 需要 | 不需要 |
| 探针数量 | 支持静态探针数量有限 | 可以Hook几乎所有内核函数 |
- Tracing 内核框架对比:
.png)
- eBPF与内核模块对比:
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
3 eBPF 如何工作
3.1 eBPF 虚拟机
eBPF 虚拟机和系统虚拟化(如kvm)有着本质不同:
- 系统虚拟化基于 x86 或 arm64 等通用指令集,足以完成完整计算机的所有功能。
- eBPF 只提供有限的指令集,用于完成一部分内核功能,远不足以模拟完整的计算机。
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情;
- 内核中的 BPF 字节码负责在内核中执行特定事件,如需要也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间;
.png)
3.2 eBPF 模块
.png)
-
**eBPF 辅助函数:**它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
-
eBPF 验证器(Verifier):它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
静态验证:类似静态分析,主要做边界检查,防止内存访问越界。
-
**eBPF 存储模块:**是由 ::11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈::组成。这个模块用于控制 eBPF 程序的执行。
关于eBPF存储模块的寄存器:
-
R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;
-
R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;
-
R10 是一个只读寄存器,用于从栈中读取数据。
-
-
**即时编译器(JIT):**将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
-
**BPF 映射(map):**用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
.png)
4 eBPF 程序编写
4.1 eBPF程序分类
-
内核代码(Kernel code):经过编译器(LLVM)编译为eBPF字节码,使用eBPF JIT加载到内核执行。目前大部分工具使用C编写,包括BCC和libbpf。
备注:bpftrace提供一种易用脚本高效 tracing ,原理是用 LLVM 将脚本转化为 eBPF 字节码。
-
用户代码(User code):负责与eBPF Map 交互,接收 eBPF 内核程序发送的数据。本质是通过 Linux 提供的 syscall 完成的,可以用任何语言实现。如:BCC → python,libbpf → c/cpp,tracee → go。
eBPF使用:bpftrace, BCC(python), ply
eBPF开发:libbpf
4.2 代码示例
hello.bpf.c:内核程序
/// \file: hello.bpf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
// Insert section 1: 指定 license,用于 verify.
char LICENSE[] SEC("license") = "Dual BSD/GPL";
// Insert section 2: 在 do_sys_open 入口放置 kprobe 探针
// 系统调用进入触发:打印信息
SEC("tracepoint/syscalls/sys_enter_execve")
int BPF_PROG()
{
char msg[] = "Hello, World!";
bpf_trace_printk(msg, sizeof(msg));
return 0;
}
hello.c :用户程序
/// \file: hello.c
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "hello.skel.h"
static int libbpf_print_fn(
enum libbpf_print_level level,
const char *format,
va_list args)
{
return vfprintf(stderr, format, args);
}
static void bump_memlock_rlimit(void)
{
struct rlimit rlim_new = {
.rlim_cur = RLIM_INFINITY,
.rlim_max = RLIM_INFINITY,
};
if(setrlimit(RLIMIT_MEMLOCK, &rlim_new)) {
fprintf(stderr, "Failed to increase RLIMIT_MEMLOCK limit!\n");
exit(1);
}
}
int main(int argc, char **argv)
{
struct hello_bpf *skel;
int err;
// 设置 libbpf error 和 debug 信息回调
libbpf_set_print(libbpf_print_fn);
// 放松内存限制
bump_memlock_rlimit();
// 打开 BPF 应用
skel = hello_bpf__open();
if(!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
// 加载验证 BPF 程序
err = hello_bpf__load(skel);
if(err) {
fprintf(stderr, "Faied to load and verify BPFskeleton\n");
goto cleanup;
}
// 绑定tracepoint handler
err = hello_bpf__attach(skel);
if(err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see out put of the BPF programs.\n");
for(;;) {
// 启动 BPF 程序板机
fprintf(stderr, ".");
sleep(1);
}
cleanup:
hello_bpf__destroy(skel);
return -err;
}
- 编译运行:
cmake .
make hello
sudo ./hello
.png)
5 eBPF未来
- BCC
- libbpf
- CO-RE(Compile Once, Run Everywhere)
.png)
.png)
问题:
- 移植性差,依赖内核版本
- 每次运行都需要编译
- 依赖大:Clang/LLVM + Linux headers
- 资源消耗多:Clang/LLVM编译消耗CPU/内存
附件
附件1. 数据源与内核框架映射:
.png)
附件2. BPF架构原理图:
.png)
附件3. eBPF架构图(另一种视角):
.png)
附件4. eBPF拓展&基础设施:
.png)
.png)
附件5. eBPF指令集:
.png)
.png)
qemu 源码分析
FX!32
参考资料:
FX!32 是一个商业仿真软件,允许 Intel x86 的 Win32 程序运行在基于 DEC Alpha 的 Windows NT 的系统上(1997)。
- 开发公司:Digital Equipment Corporation
- 开发时间:1997
- 指令集翻译:x86 -> Alpha
- 关键词:剖析(Profile)、透明(Transparent)启动和加载
"透明的启动和加载"是指:
在用户使用应用程序时,他们不需要知道或理解应用程序是如何在他们的系统上启动和加载的。这个过程对用户来说是"透明"的,也就是说,他们可以像在原生环境中一样自然地运行应用程序,而无需进行任何特殊的操作或设置。
FX!32 组成
DIGITAL FX!32的软件组成模块主要包括以下几部分:
- 模拟器(Emulator):模拟器负责执行x86代码,这包括在应用程序被翻译之前或无法翻译的部分。模拟器还会生成执行剖析数据,供翻译器使用。
- 翻译器(Binary Translater & Opt):翻译器在后台运行,根据剖析数据将x86代码翻译成Alpha代码。翻译后的代码可以提高应用程序的性能,达到与原x86平台相当的水平;
- 代理和运行时(Agent & Runtime):代理提供透明的启动和加载x86程序的功能。运行时会重定位x86 image,并为系统调用的代码提供helper函数;
- 数据库和服务器(Database & Server):数据库存储 Profile 和翻译 Image,以及应用程序的配置信息。服务器负责维护数据库和调度翻译过程。
执行过程
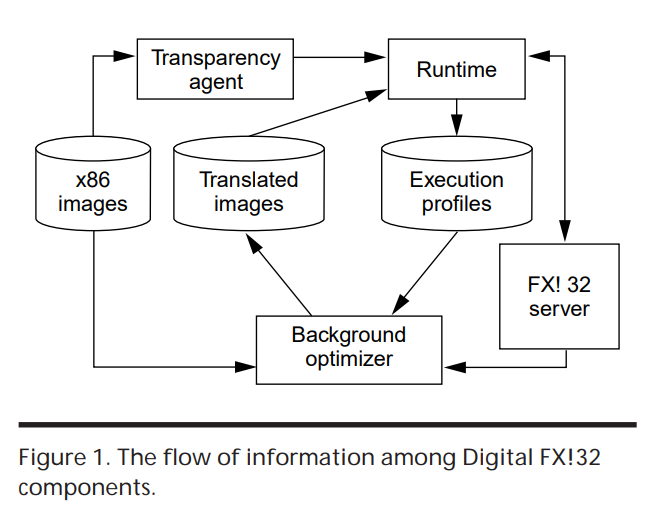
DIGITAL FX!32的程序执行过程如下:
- 启动和加载(Load images):当用户启动一个x86的32位程序时,FX!32的 Agent 开始透明的启动和加载过程。Runtime 会重定位x86镜像;
- 模拟执行(Emulate exec):在应用程序被翻译之前或无法翻译的部分,使用模拟器来执行x86代码。这个过程可能会比在原生x86系统上运行慢一些,但是它允许任何x86的32位程序在Alpha系统上运行;
- 剖析和翻译(Profile & Translate):模拟器在执行x86代码的同时,会生成执行剖析数据。这些数据会被送到后台的翻译器。翻译器根据剖析数据将x86代码翻译成Alpha代码。这个过程在在后台进行;
- 优化执行(Opt exec):当翻译后的Alpha代码可用时,运行时会使用这些代码替换原来的x86代码。因为Alpha代码的执行效率更高,所以应用程序的性能会得到提升;
- 数据库和服务器(Database & Server):所有的 Profile 和翻译后的 Image 都会被存储在数据库中,以便于下次执行时使用。服务器负责维护数据库和调度翻译过程。当有新的剖析数据生成时,服务器会更新数据库,并根据新的数据调度翻译过程。当有新的翻译 Image 生成时,服务器也会更新数据库,并确保下次执行时使用最新的翻译 Image。
备注:这里的 Image 类似于 Code Block
数据库
DIGITAL FX!32的数据库存储了以下数据的条目和细节(本质上是 DLL 文件):
- 镜像索引(Image ID):Guest Image Entry 经过 hash 函数生成索引;
- 剖析数据(Profile):模拟器在执行x86代码的同时,会生成执行剖析数据。这些数据包括了程序的运行情况:
- SPC-TPC 地址对:x86 code entry -> Alpha code entry 地址对
- 未对齐引用的指令地址:一些指令地址未对齐,需要二次取指;
- CALL 指令目标地址:使用 CALL 指令调用的指令块地址;
- (个人设想)Image 执行次数
- 翻译镜像(Translated Image):翻译器将x86代码翻译成Alpha代码后,会将翻译后的代码存储在数据库中。这些翻译后的代码被称为翻译镜像。当同一个程序再次运行时,系统可以直接使用这些翻译镜像,而无需再次进行翻译,从而提高了程序的启动速度和运行效率。
- 镜像重定位 section:包含 x86 image 引用的重定位信息的部分(如果 x86 image 未在其首选基地址加载则必须重新定位这些引用;
Profile
每当模拟相关指令时,通过将值插入运行时哈希表来收集 Profile。例如:
- 当模拟 CALL 指令时,模拟器会记录调用的目标;
- 当卸载 Image 或应用程序退出时,将处理运行时维护的哈希表,并写入该 Image 的 Profile;
- 于此同时,运行时判断如果该 Image 是热点代码,将会调用翻译器;
- Server 将翻译后的 Image 和 Profile 进行处理,传入数据库;
- 如果非热点代码,Server 处理此 Profile,将其与任何先前的 Profile 合并。
实验表现
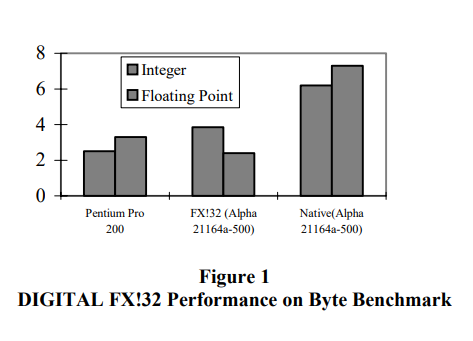
Rust
TLA
参考资料:
概念
想象一下,我们正在为一家银行构建电汇服务。用户可以向其他用户进行转移。作为一项要求,我们不允许任何会透支用户帐户或使其低于零美元的电汇:如果您尝试转移超过您拥有的金额,警卫会阻止您。
def transfer(from, to, amount)
if (from.balance >= amount) # guard
from.balance -= amount; # withdraw
to.balance += amount; # deposit
现在考虑两个变化:
- 用户可以一次启动多个传输;
- 转移步骤是非原子的。一个转移可以开始并(可能)完成,而另一个转移正在进行。
---- MODULE wire ----
(* 导入模块 *)
EXTENDS TLC, Integers
(* People 和 Money 是集合:唯一、无序 *)
People == {"alice", "bob"}
Money == 1..10
NumTransfers == 2
(* --algorithm wire
(* [People -> Money] 也是一个集合
变量 acct 不是一个固定值,它是 100 个不同值之一
*)
variables
acct \in [Perople -> Money];
(* NoOverdrafts 是一个量词:
如果每个帐户都是 >= 0,则为 true,否则为 false
*)
define
NoOverdrafts ==
\A p \in People:
acct[p] >= 0
end define;
(* 使用 NumTransfers == 2:
两个 wire 进程同时运行
*)
process wire \in 1..NumTransfers
variable
amnt \in 1..5;
from \in People;
to \in People
begin
Check:
if acct[from] >= amnt then
Withdraw:
acct[from] := acct[from] -amnt;
Deposit:
acct[to] := acct[to] + amnt;
end if;
end process;
end algorithm; *)
====
meson 使用
参考资料:
meson 简介
meson 和 make 类似,需要编写一个描述文件meson.build来告诉它需要如何构建,meson根据 meson.build 中的定义生成具体的构建定义文件 build.ninja,ninja 根据 build.ninja 完成具体构建。
meson 基本使用
- 首先在源码根目录下创建
meson.build文件:该文件定义了learn_meson这个工程,并定义了hello这个可执行程序(其使用了源文件test.c)。
project('learn_meson', 'c')
executable('hello', 'test.c')
- 在需要构建的源码根目录运行:表面程序构建目录在build文件夹内。
meson setup build
- 通过配置文件构建:其中,rv_cross_file是指定一些构建要用的参数,当然你的系统里要有riscv的工具链。rv_cross_file内容如下:
[host_machine]
system = 'linux'
cpu_family = 'riscv64'
cpu = 'riscv64'
endian = 'little'
[properties]
c_args = []
c_link_args = []
[binaries]
c = 'riscv64-linux-gnu-gcc'
cpp = 'riscv64-linux-gnu-g++'
ar = 'riscv64-linux-gnu-ar'
ld = 'riscv64-linux-gnu-ld'
objcopy = 'riscv64-linux-gnu-objcopy'
strip = 'riscv64-linux-gnu-strip'
- 构建成功后,编译程序:
meson compile -C build
- 可以在build目录下看见生成的可执行程序:看到编译好的hello是动态链接的。进入build,运行meson configure可以看到default_library一项是shared,meson configure显示构建的配置,默认为动态链接,可以使用如下命令修改为静态链接:(注意,要在build下运行)
meson configure -Ddefault_library=static
meson 生成配置文件
scoop 使用
参考资料:
Git 使用
参考资料:
stable diffusion 部署
参考资料:
mdbook 使用
参考链接:
hugo 静态博客部署
参考资料:
实用网站
文件处理
科研工具
矩阵分析复习
一、题目类型与分值
- 计算解 (4小题) ,共45分;
- 问题求解题 (2小题) ,共25分;
- 证明题 (3小题) ,共30分
二、复习提纲
- 矩阵的Hadamard积和Kronecker 积
Jordan标准型

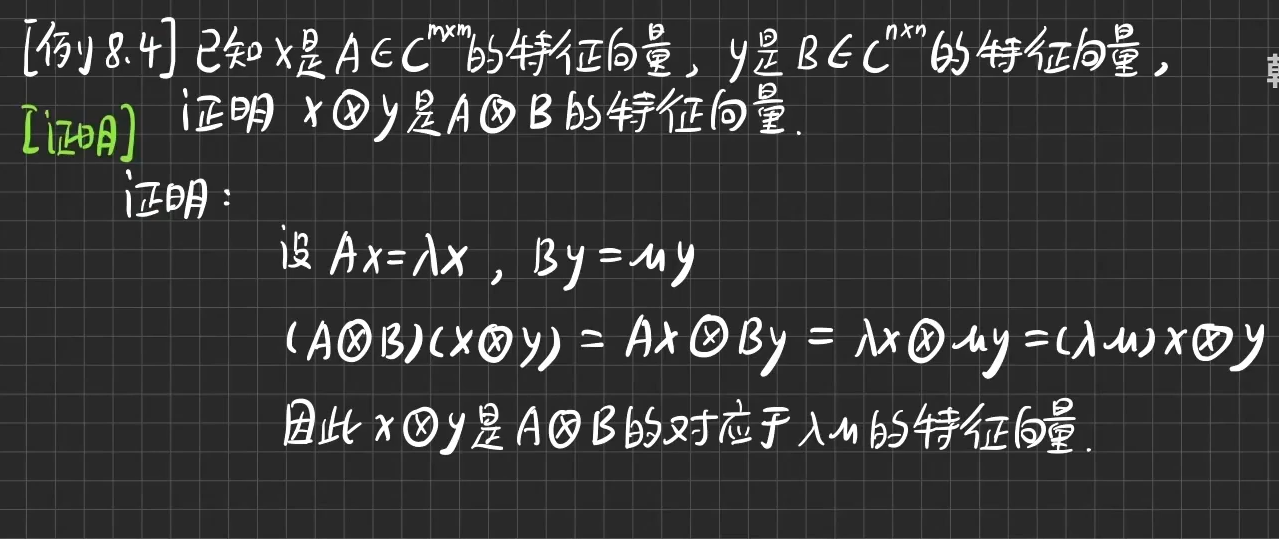
-
矩阵的迹
-
求实矩阵函数的 Jacobian 矩阵和梯度矩阵:
-
求矩阵 $A$ 的Moor-Penrose逆 $ A^{\dagger } $
满秩分解法
- 求到矩阵 $A$ 列空间上的投影算子和正交投影算子
投影算子: $$ P=AA^{\dagger } $$ 正交投影算子: $$ I-P=I-AA^{\dagger } $$
- 求与A最接近的正交矩阵
考虑正交强迫一致问题: $$ \min_{Q^TQ=I} \left | A-BQ \right | ^{2} {F} $$ 化简: $$ \left | A-BQ \right | ^{2} {F}=tr(AA^T)-2tr(Q^TB^TA)+tr(Q^TB^TBQ) $$ 即求: $$ \min{Q^TQ=I} tr(Q^TB^TA) $$ 设 $ B^TA = U\Sigma V^T$ ,正交矩阵$ Z=V^TQ^TU $ ,则有: $$ tr(Q^TB^TA) = tr(Q^TU\Sigma V^T) = tr(V^TQ^TU\Sigma) = tr(Z\Sigma) $$ 其中: $$ tr(Z\Sigma)=\sum{i=1}^{n}z_{ii}\sigma_{i} \le \sum_{i=1}^{n}\sigma_{i} $$ 当且仅当 $ z_{ii} = 1 $ 时等号成立,即 $ Z=I, Q=UV^T$
特例:当 $ B=I $ 时,$ Q=UV^T $ 即 $ A $ 最接近的正交矩阵。
- 正则化非负矩阵分解的迭代法则 (加法和乘法迭代法则) :
平方 Euclidean 距离 $$ \min_{A,S} D_{E}(X||AS) = \frac{1}{2} \left | X-AS \right | ^2_{F} $$ 迭代公式(加法形式): $$ \left{\begin{matrix} a_{ik} \longleftarrow a_{ik} - \mu_{ik} \frac{\partial D_E(X || AS)}{\partial a_{ik}} \s_{kj} \longleftarrow s_{kj} - \eta_{kj} \frac{\partial D_E(X || AS)}{\partial s_{kj}}
\end{matrix}\right. $$
其中: $$ \left{\begin{matrix} \frac{\partial D_E(X || AS)}{\partial A} = -(X-AS)S^T \\frac{\partial D_E(X || AS)}{\partial S} = -A^T(X-AS)
\end{matrix}\right. $$ 则可以化简为乘法形式,令: $$ \left{\begin{matrix} \mu_{ik}=\frac{a_{ik}}{[ASS^T]{ik}} \\eta{kj}=\frac{s_{kj}}{[A^TAS]_{kj}}
\end{matrix}\right. $$
乘法形式: $$ \left{\begin{matrix} a_{ik} \longleftarrow a_{ik} \frac{[XS^T]{ik}}{[ASS^T]{ik}} \ s_{kj} \longleftarrow s_{kj} \frac{[A^TX]{kj}}{[A^TAS]{kj}} \end{matrix}\right. $$ K-L 散度
- $ L_1 $ 正则化最小二乘问题解的充要条件;
$ L_1 $ 正则化最小二乘问题: $$ minJ(\lambda, x) = \frac{1}{2} \left | y-Ax \right | _{2} ^{2} + \lambda \left | x \right | _{1} $$ 次梯度向量: $$ \nabla_x J(\lambda, x) = -A^{T}(y-Ax) + \lambda \nabla_x \left | x \right | _{1} $$
设 $ c = A^{T}(y-Ax) $,则 $L_1$ 正则化最小二乘问题的平稳条件(充要条件): $$ c = \lambda \nabla_x \left | x \right | _{1} $$
其中: $$ \nabla_{x_{i}} \left | x \right | {1} = \left{\begin{matrix} {+1} \qquad \quad x{i} > 0 \\left [ -1, +1 \right ] \qquad x_{i} = 0 \{-1} \qquad \quad x_{i} < 0 \end{matrix}\right. $$ 即: $$ c_i= \left{\begin{matrix} {+\lambda} \qquad \quad x_{i} > 0 \\left [ -\lambda, +\lambda \right ] \qquad x_{i} = 0 \{-\lambda} \qquad \quad x_{i} < 0 \end{matrix}\right. $$
- Rayleigh商和广义Rayleigh商的最小化或最大化问题的解:
Hermitian 矩阵 $ A $ 的 Rayleigh 商为: $$ R(A,x)=\frac{x^HAx}{x^Hx} $$ 将最小二乘问题简化,令 $ x^Hx=1 $ ,此时 $ R(A,x)=x^HAx $
构造Lagrange乘子函数 $ L(x,\lambda) = x^HAx - \lambda (x^Hx-1) $
对 $ x $ 求梯度并令其为 $0$ ,得到 $ 2Ax - 2\lambda x =0 $
等价于 $ \lambda_{i} $ 为矩阵 $A $ 第 $ i $ 个特征值,$ x_i $ 为其特征向量,故: $$ R(A,x_i)=\lambda_i $$ 得到结论:当取 $A $ 的最大特征向量 $ x_{max} $ 时,Rayleigh 商有最大值即为 $ \lambda_{max} $ ;同理取 $A $ 的最小特征向量 $x_{min}$ 时,Rayleigh 商有最小值即为 $ \lambda_{min} $
广义 Rayleigh 商中,如果 $B$ 为正定矩阵: $$ R(A,B,x)=\frac{x^HAx}{x^HBx} $$ 设新的向量 $ \tilde{x}=B^{1/2}x $ ,代入得: $$ R(A,\tilde{x})=\frac{\tilde{x}^H(B^{-1/2})^HAB^{-1/2}\tilde{x}}{\tilde{x}^H\tilde{x}} $$ 故矩阵对 $(A,B)$ 的广义 Rayleigh 商即为 $ (B^{-1/2})^HAB^{-1/2}$ 的标准 Rayleigh 商
若 $ (B^{-1/2})^HAB^{-1/2} $ 的特征值分解为: $$ (B^{-1/2})^HAB^{-1/2}\tilde{x}=\lambda \tilde{x} \ B^{-1}Ax=\lambda x \ Ax=\lambda Bx $$ 此表明矩阵 $ (B^{-1/2})^HAB^{-1/2}$ 的特征值分解与矩阵对 $(A,B)$ 的广义特征分解等价。故 $ x$ 取矩阵对 $(A,B)$ 的广义特征值对应的最大特征向量时,广义 Rayleigh 商最大化。
- 实对称矩阵或Hermitian矩阵的特征值必为实数
证明 Hermitian 矩阵特征值均为实数,属于不同特征值的特征向量正交
一、原式子: $$ Ax=\lambda x $$ 两边取共轭转置: $$ x^HA^H=\bar{\lambda} x^H $$ 两边右乘 $x$ : $$ x^HA^Hx=\bar{\lambda}x^Hx \ x^HAx=\bar{\lambda}x^Hx \ \lambda x^Hx=\bar{\lambda} x^Hx $$ $x$ 非0向量,则 $ \lambda - \bar{\lambda} = 0$ ,故 Hermitian 矩阵的特征值必为实数
二、证明正定矩阵的特征值都大于0
原式子: $$ Ax=\lambda x \ x^TAx=\lambda x^Tx $$ 由于 $ x^TAx > 0 $,又有 $x$ 非0向量,$ x^Tx >0 $
故: $$ \lambda =\frac{x^TAx}{x^Tx} > 0 $$ 得证
- 总体最小二乘问题的解。
如何解
Scoop 安装
参考链接:
步骤 1:在 PowerShell 中打开远程权限
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
步骤 2:自定义 Scoop 安装目录
irm get.scoop.sh -outfile 'irm get.scoop.sh -outfile 'install.ps1'
.\install.ps1 -ScoopDir 'D:\app\Scoop' -ScoopGlobalDir 'D:\app\GlobalScoop_Path' -NoProxy
步骤3:设置国内镜像
iwr -useb https://gitee.com/glsnames/scoop-installer/raw/master/bin/install.ps1 | iex
scoop config SCOOP_REPO 'https://gitee.com/glsnames/scoop-installer'
scoop update
步骤4:更新scoop
scoop install git
scoop update
步骤5:scoop下载加速
scoop install aria2
scoop config aria2-warning-enabled false
# aria2 在 Scoop 中默认开启
scoop config aria2-enabled true
# 关于以下参数的作用,详见aria2的相关资料
scoop config aria2-retry-wait 4
scoop config aria2-split 16
scoop config aria2-max-connection-per-server 16
scoop config aria2-min-split-size 4M
注意:下载错误建议关闭
aria2scoop config aria2-enabled false # scoop config aria2-enabled true 开启
步骤6:安装bucket
scoop bucket add extras
scoop bucket add java
scoop bucket add versions
scoop bucket add dorado https://github.com/chawyehsu/dorado
Linux 字体安装
参考链接:
步骤5:安装字体
#更改文件夹权限
sudo chmod -R 777 /usr/share/fonts/truetype/windows-font
cd /usr/share/fonts/truetype/windows-font
# 如果提示 mkfontscale: command not found
# 在Ubuntu下运行如下命令
# sudo apt-get install ttf-mscorefonts-installer
# 在cent os下运行如下命令
# yum install mkfontscale
sudo mkfontscale
sudo mkfontdir
# 如果提示 fc-cache: command not found
# 在Ubuntu下运行如下命令
# sudo apt-get install fontconfig
# 在cent os下运行如下命令
# yum install fontconfig
sudo fc-cache -fv
win 终端美化
参考资料:
步骤1:安装zsh
sudo apt-get install zsh